Abstract
News sentiment analysis is crucial for understanding market behaviour and making enhanced decisions in financial domains. This paper presents a developed multi-agent system that is scalable for financial sentiment analysis; it uses RabbitMQ for effective communication and to distribute the load in an enhanced manner. In this regard, four different models were implemented and compared: a Naive Bayes model, two LSTM models (one with GloVe embeddings and another one with pretrained DistilBERT embeddings), and a Logistic Regression model. Each of them was trained and then tested on the labelled financial news dataset, the imbalance of which was addressed using an LLM, whereas the LSTM model, which incorporated DistilBERT embeddings, had the best performance with an accuracy of 85%. The multi-agent system includes both the sentiment analysis agents and the action agents. RabbitMQ is the fabric that lets multiple services talk with each other and scale seamlessly. The key action agents, the positive and negative action agents, mint an NFT and perform distributed ledger transactions, respectively, based on the sentiment analysis agent’s prediction. This work has underlined the efficiency of transform-based architectures for sentiment extraction in sophisticated financial texts. It also shows how multi-agent frameworks can be applied to boost efficiency in large-scale and real-time sentiment analysis.
Keywords: sentiment analysis, DistilBERT, transformer, distribution, model, text processing, message broker, multi-agent system, scalable.
Introduction
Sentiment defines a view or opinion that is held or expressed. This can be shown towards an entity, an event, a person, or an inanimate object. Given that humans are social beings, there will always be mediums through which people express how they feel regarding an entity. In a world of technological advancement, where communication has been transformed right from the days of strictly oral communication to it being aided by technology for people to share their feelings through mobile phones, blogging, newspaper articles, tabloids, microblogging channels such as Facebook, X, or video sharing platforms such as Tiktok, YouTube amongst others. These sentiments can be widely categorized into three (3) main types; viz 1) positive, 2) negative, and 3) neutral sentiments. Hence, when people make their sentiments known through these channels, an analyst can come to a degree of certainty about what the general sentiment is over an issue. This provides a much-needed feedback loop for decision scientists and policymakers alike to either change the mind of the public or make decisions that ride on the momentum.
In 2022, according to the World Economic Forum, there will be 8.58 billion mobile subscriptions with over 5.4 billion people worldwide having at least one mobile subscription. Furthermore, Datareportal has it that 95.9% of internet users worldwide use the internet at least occasionally on a mobile device, and mobile phones currently make up 56.9% of all online time and 60% of all web traffic worldwide. One can aggregate how people feel regarding a topic. On YouTube, this can be inferred through the like or dislike buttons, comment section, posts, or in a real-world scenario, through protests or advocacy that encourages an action.
The financial world is no different, as the availability and democratization of online platforms with the ubiquitousness of mobile phones have made it possible to aggregate how people feel at each point in time. A popular perspective on this is on speculative assets such as cryptocurrency where those looking to buy, sell or trade on a "coin", i.e. an asset, do so by seeking how active the community is regarding that currency. The opinions of these communities can be gotten solely through online platforms such as X (formerly Twitter), Facebook, Reddit, Discord, Telegram, and YouTube amongst others. As a result, an investor may be able to derive the sentiment around this asset and come to a conclusion regarding what investment decision they are to take. Sentiment analysis in finance entails the use of algorithms to analyze textual data sourced from social media, news articles, and other sources to assess the overall mood of the market. Investors and traders can better grasp how public opinion and feelings impact financial markets with the use of this analysis, just like the example of the crypto trader.
The automation of sentiment analysis comes with some challenges because of the complexity in the nature of human language and ways of communication. This includes major problems involving pretexts brought about by sarcasm and irony, where positive terms might mean negative sentiments and vice versa; this sometimes leads to their incorrect interpretation by algorithms [58]. Additionally, identifying negation is a big challenge, as every negation term does not signify fully negative sentiments in the data. This is even more challenging in the case of multilingual data to be dealt with, wherein algorithms have to learn subtlety across languages. The usage of various forms of emojis and other expressions in today’s communication modality also makes the interpretation tough.
The financial industry generates volumes of data daily, which needs complex systems for processing and analysis. The news, earnings reports, and social media contributions have resulted in a lot of unstructured data emanating from modern financial systems. This information is of prime importance for deriving actionable insights in due time to make proper decisions on trading, risk management, and customer interaction.
The scalable distributed MAS will be one holistic approach to dealing with large financial datasets. Such systems take advantage of the power of parallel processing and decentralized decision-making to advance higher throughput in data processing for quicker insights into the data. Other significant advantages are improved decision-making, flexibility, and cost-effectiveness.
Objective
The objective of this work is to develop a scalable, distributed Multi-Agent System (MAS) for financial sentiment analysis on financial news data using RabbitMQ. This aims to:
-
Analyze the challenges being faced in handling large-scale textual financial data.
-
Compare and evaluate the performance of LSTM, Naive Bayes, and Logistic Regression models in addition to different embedding methodologies such as word count, GloVe and DistilBERT on real-life financial news data.
-
Develop a scalable MAS architecture tailored for financial applications.
-
Implement the execution of distributed ledger transactions as response agents in the MAS architecture.
-
Assess the potential benefits and limitations of implementing such systems in the financial industry.
By achieving these goals, we aim to contribute to the development of more efficient and reliable data processing systems, not only in the financial sector but across other domains such as customer and brand management, product development and market research, social media monitoring, governance and competitive analysis. This ultimately enhances decision-making and operational efficiency in these sectors.
Methodology
A general overview of the MAS architecture is given below.
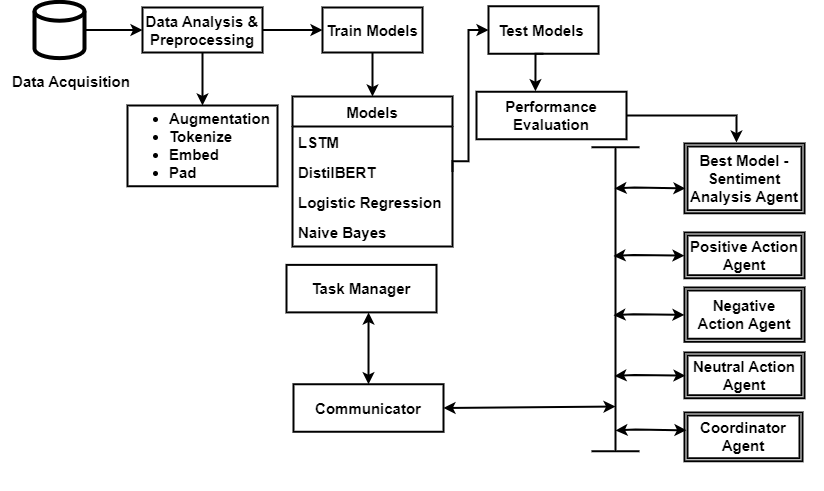
The architecture gives a simplistic breakdown which commences with the data acquisition process and ends with the agents interacting according to the outcome of the sentiments in a text. Data can either be proprietary or open source. For the sake of this research, we use publicly available data from Kaggle (FinancialPhraseBank). The data derived may not be in the best format needed for analysis and modelling. Hence, it is required to pre-process such text data by using some of the required techniques applicable to the model in application. As a result, different models may require different preprocessing methods for text.
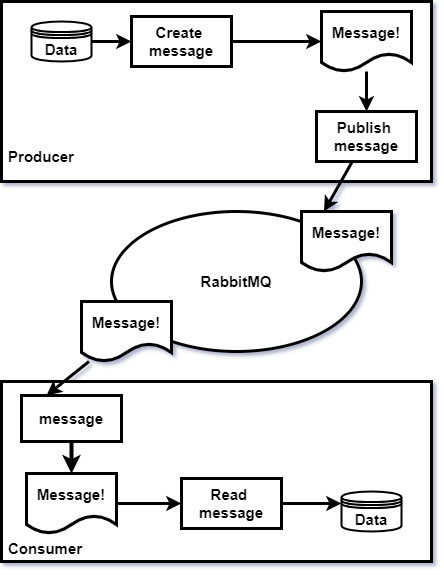
RabbitMQ is a well-known messaging queue platform used for point-to-point communication. This describes a paradigm where producers send messages to queues from where the consumers consume the data in order [54]. The messages are stored in a queue until they are retrieved, and are asynchronous such that the producers and consumers do not need to simultaneously interact with the queue.
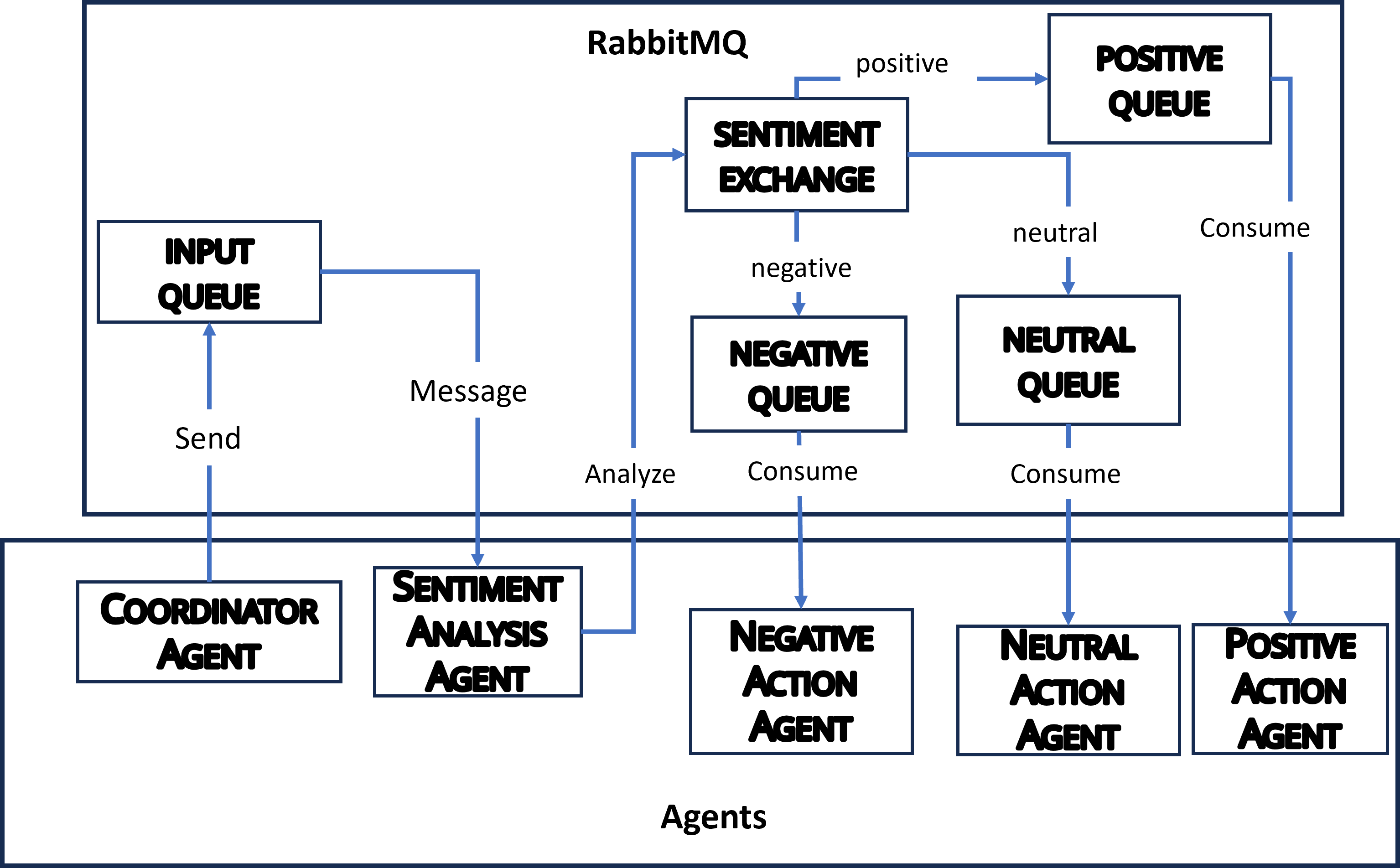
This project demonstrates a distributed architecture where agents collaborate to process user input efficiently:
- The Coordinator Agent collects input from users.
- The Sentiment Analysis Agent determines the sentiment (positive, neutral, or negative) using a machine learning model.
- Specialized Action Agents perform actions based on the sentiment:
- Positive Action Agent: Handles positive sentiments and mints NFT as response action.
- Neutral Action Agent: Handles neutral sentiments. It is considered trivial.
- Negative Action Agent: Handles negative sentiments. It performs a Distributed Ledger Transaction as a response action.
Agents interact through RabbitMQ, and the sentiment is classified using a pre-trained DistilBERT model combined with logistic regression.
Features
- Distributed Architecture: Implements a robust multi-agent system using RabbitMQ for inter-agent communication.
- Sentiment Analysis: Leverages a fine-tuned DistilBERT model with a logistic regression classifier.
- Actionable Insights: Routes analyzed sentiment to specialized agents for further processing.
- Distributed Ledger Transactions: Executes transactions on the IOTA Tangle for negative sentiment.
- NFT Minting: Mints NFTs with dynamic metadata for positive sentiment.
- Dynamic Message Routing: Routes messages to action agents based on sentiment using RabbitMQ's direct exchanges.
- Timing Metrics: Logs timestamps for message receipt and processing completion to monitor performance.
Experiments

Given the data imbalance, a workflow was built using the Llama3 model using Groq. This ensures a balance in the dataset.
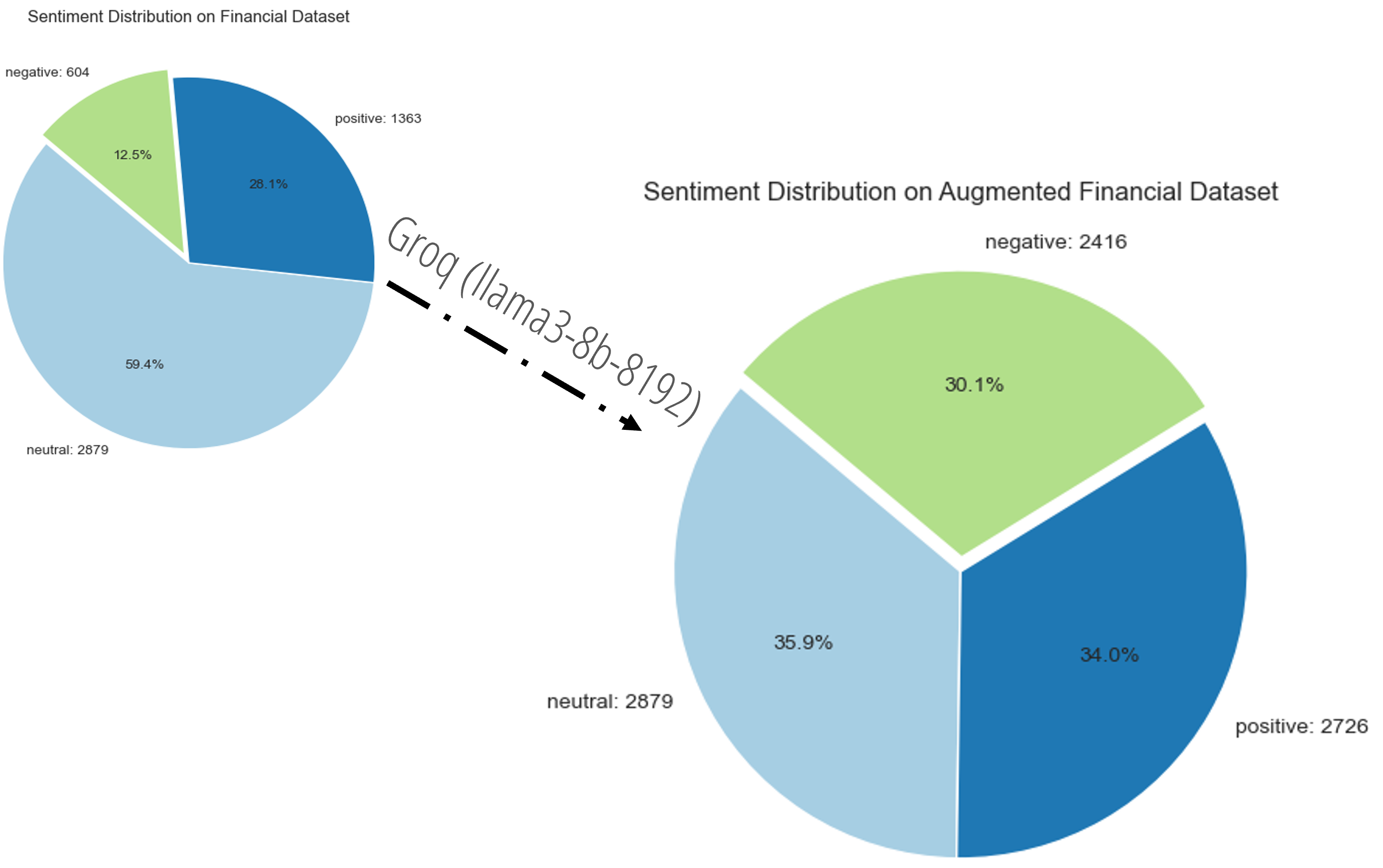
The AI assistant was asked to replicate texts that have semblance with the under-represented categories. This ensures that the augmented data is identical to the one present in the original dataset. In addition, we do not have additional data with a different distribution thereby avoiding the risk of training a model that poorly generalizes.
import os import pandas as pd from groq import Groq def augment_sentiment(df, target_ratio, sentiment_class, batch_size=10, sentiment_column='sentiment', text_column='news'): """ Augment an underrepresented sentiment class in a DataFrame using Groq API. Args: df (pd.DataFrame): Original DataFrame with sentiment and text data. target_ratio (float): Multiplier for augmenting the underrepresented class. sentiment_class (str): The sentiment class to augment (e.g., 'negative'). sentiment_column (str): Column containing the sentiment labels (default 'sentiment'). text_column (str): Column containing the text/news data (default 'news'). Returns: pd.DataFrame: A new DataFrame with augmented data added to balance the sentiment class. """ # # batch size based on API limitations # batch_size = batch_size # Set up your Groq client (ensure your API key is set in the environment) client = Groq(api_key=os.getenv('GROQ_API_KEY')) # Find the underrepresented texts (those with the specified sentiment_class) underrepresented_texts = df[df[sentiment_column] == sentiment_class][text_column].tolist() # Number of rows we want for the sentiment class current_rows = len(underrepresented_texts) target_rows = int(current_rows * target_ratio) # Number of additional examples needed needed_examples = target_rows - current_rows # Augment the underrepresented class with new examples augmented_texts = [] for i in range(needed_examples): # Select a random text from the underrepresented class to augment text = underrepresented_texts[i % current_rows] response = client.chat.completions.create( messages=[ {"role": "system", "content": "You are a data augmentation assistant."}, {"role": "user", "content": f"Generate a headline similar to: {text} and reply with response only without quotes"}, ], model="llama3-8b-8192" ) # Get the augmented text from the response augmented_data = response.choices[0].message.content augmented_texts.append(augmented_data) # Create a new DataFrame for the augmented data augmented_df = pd.DataFrame({ text_column: augmented_texts, sentiment_column: [sentiment_class] * needed_examples # Label the new examples with the same sentiment class }) # Combine the original DataFrame with the augmented data balanced_df = pd.concat([df, augmented_df], ignore_index=True) return balanced_df, augmented_df
Models

The image below shows the performance of the models trained on the financial text data.
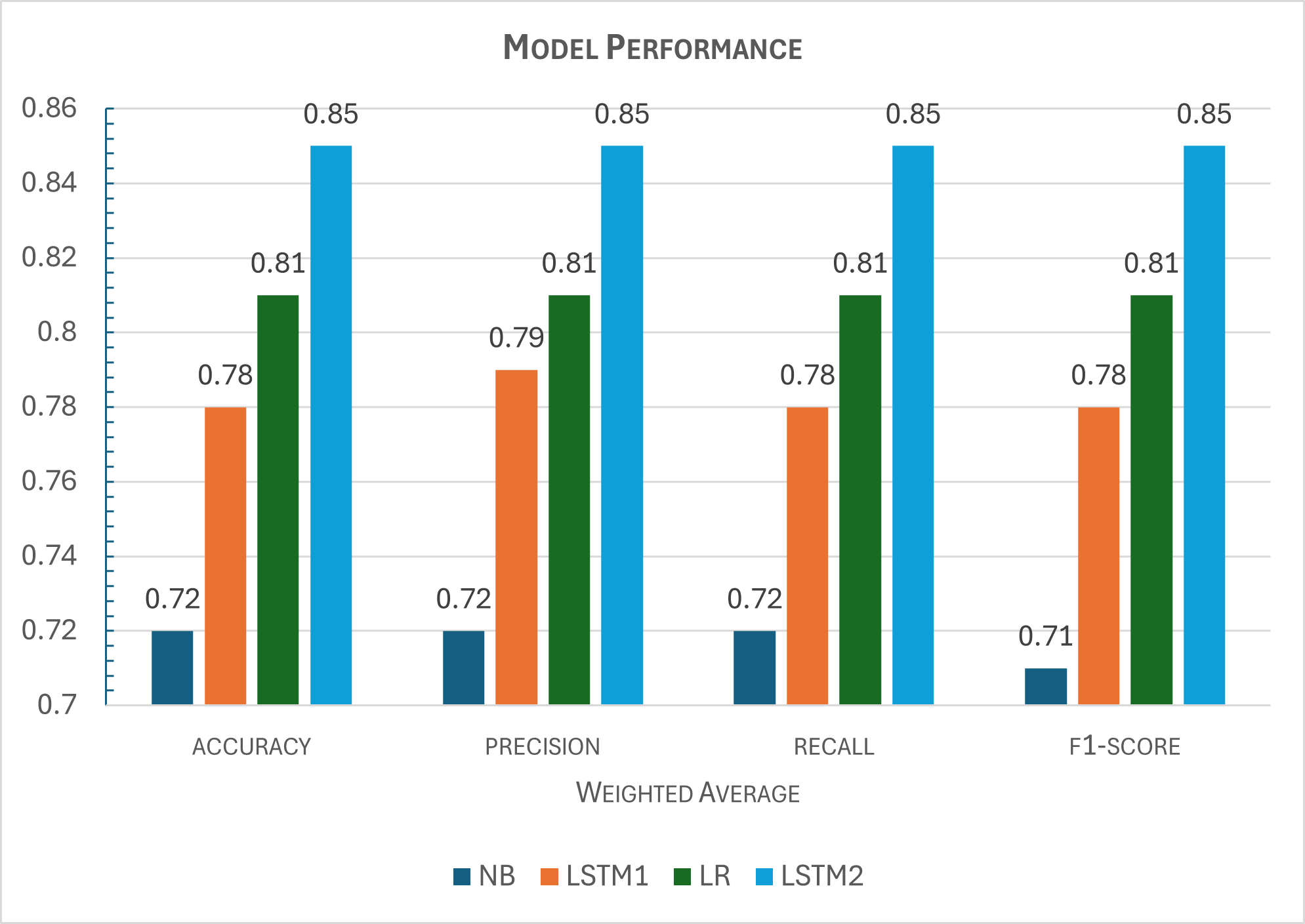
It is important to note that there is a trade-off when it comes to selecting models. For instance, looking at Table 4.4, we see that training the LR model with DistilBERT embeddings takes just 5 minutes overall. For the LSTM2 model, trained with the same DistilBERT embeddings, it takes about an hour and half. Hence, a data scien- tist will have to choose which is most important to her between model complexity, training time, and performance. Clearly, amongst the best two models, the LSTM2 model gives us the best performance, but the complexity and training time is on the high side while the LR model gives us the least training time and complexity albeit with lower performance.
Results
The image below provides an overview of the agents and their respective response actions.
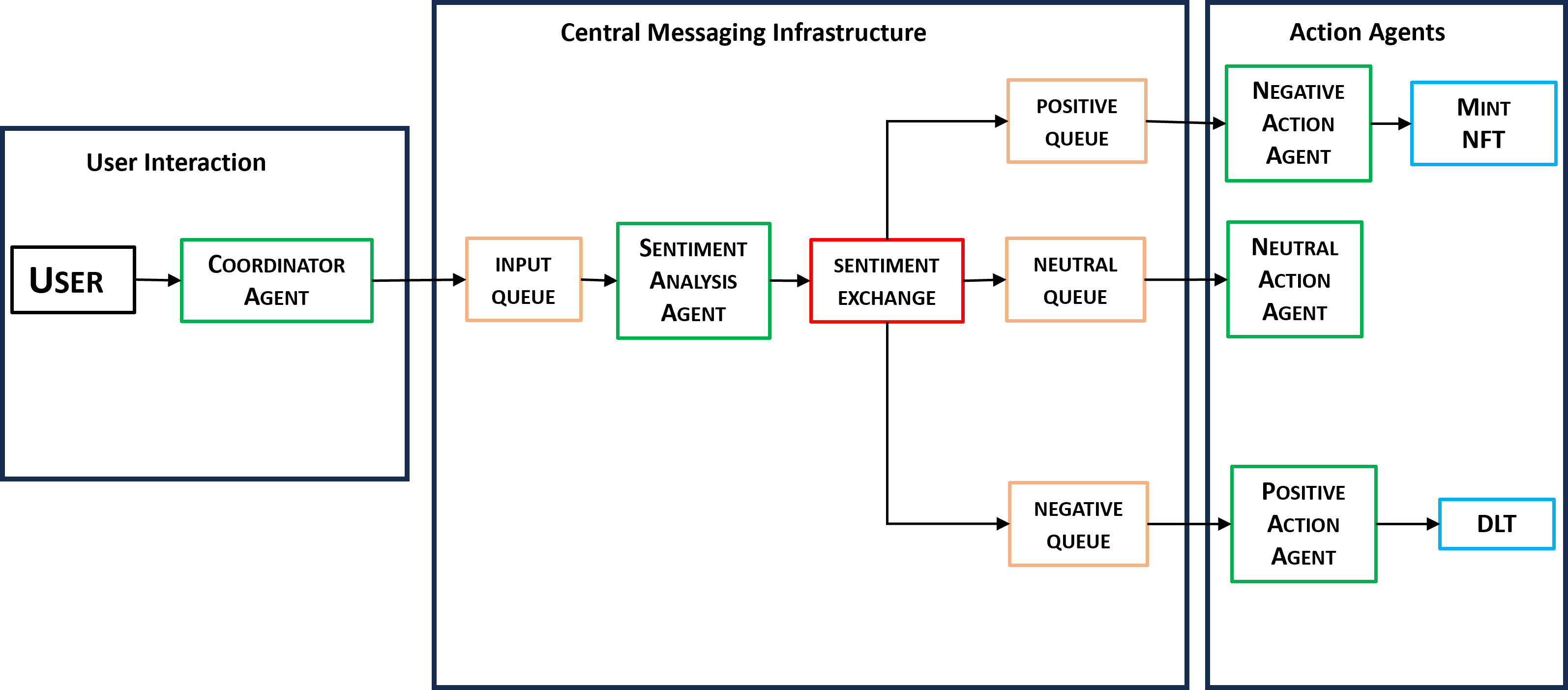
Agents in Action
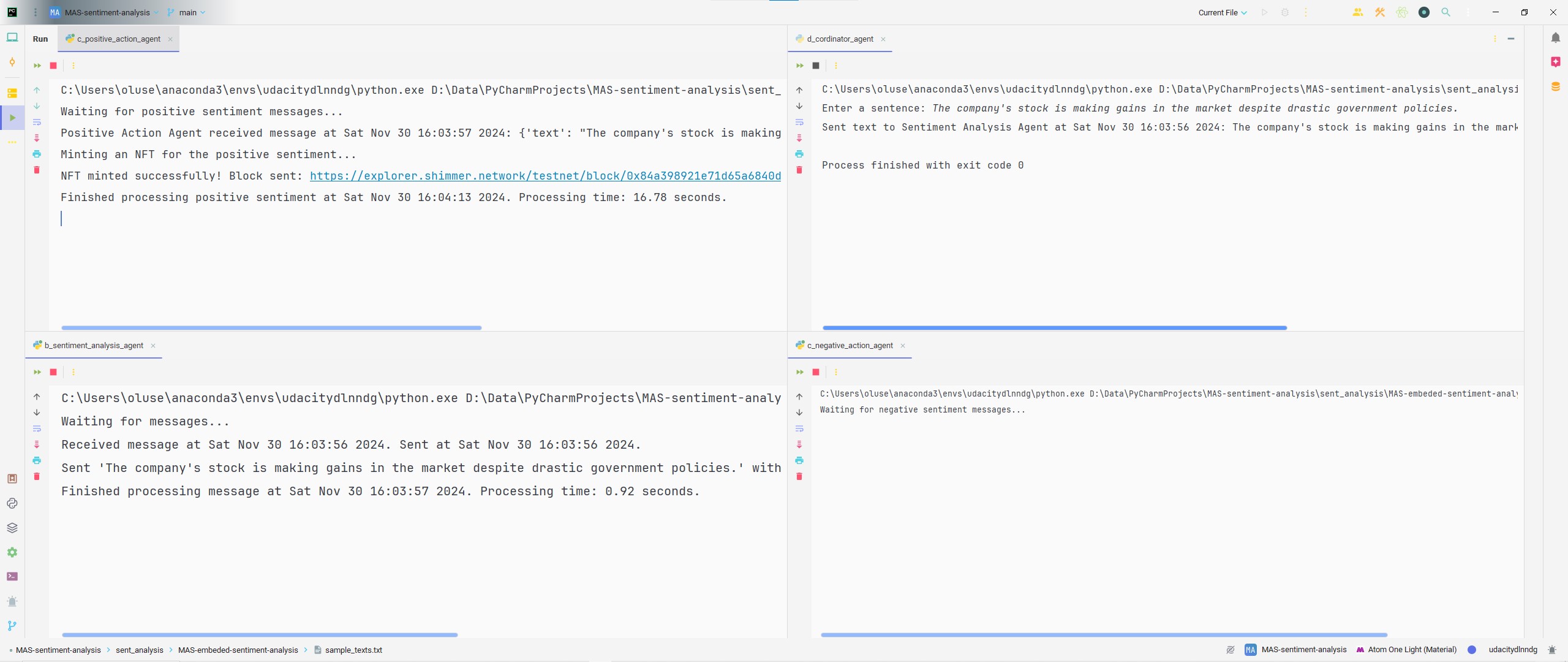
The figure below shows us our IDE with the CoA (coordinator agent) ready to collect inputs and other agents awaiting messages in the MAS.
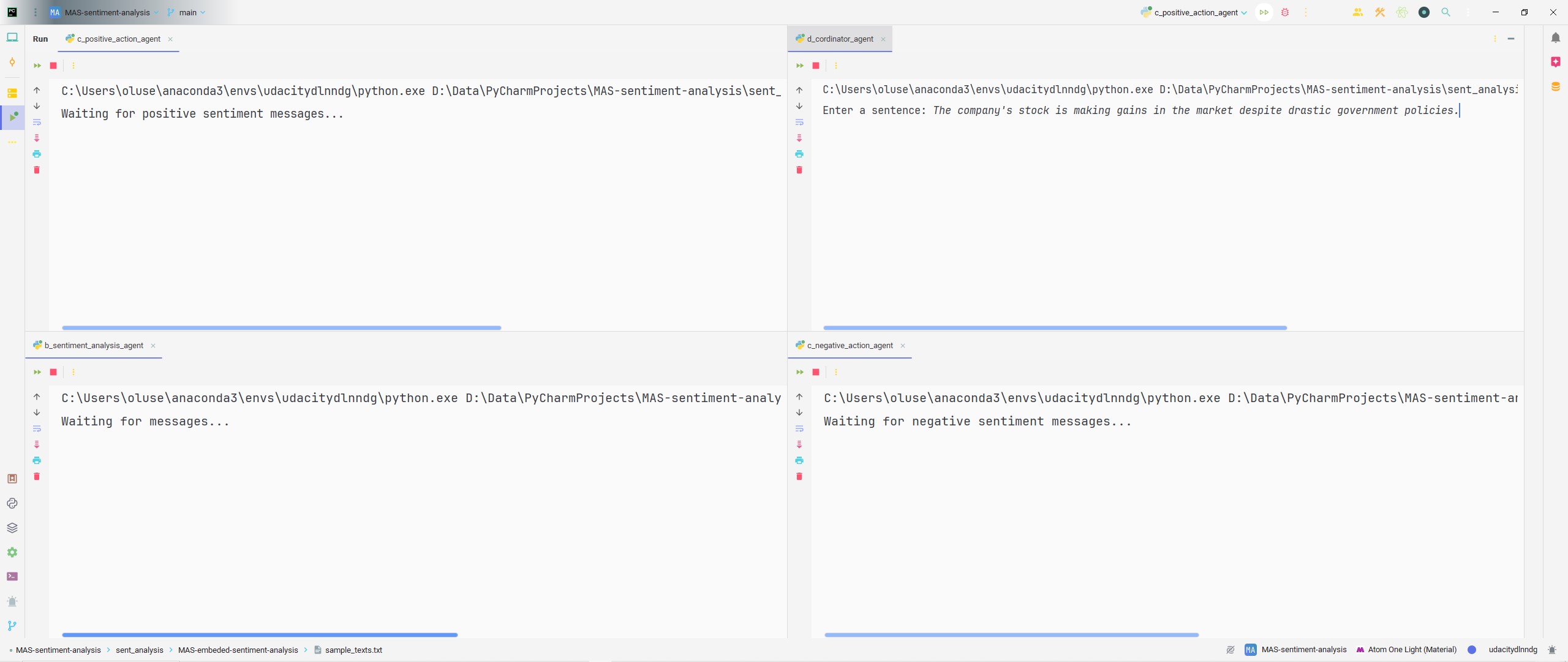
from a_connection import get_rabbitmq_connection import json import time def main(): try: # Connect to RabbitMQ connection = get_rabbitmq_connection() channel = connection.channel() # Declare the input queue channel.queue_declare(queue='input_queue') # User input text = input("Enter a sentence: ") start_time = time.time() # Prepare and send the message message = {'text': text, 'timestamp': start_time} channel.basic_publish(exchange='', routing_key='input_queue', body=json.dumps(message)) print(f"Sent text to Sentiment Analysis Agent at {time.ctime(start_time)}: {text}") # Close connection connection.close() except Exception as e: print(f"Error sending message: {e}") if __name__ == '__main__': main()
With the input The stock price tanked after the recent publication of awful earnings for the third quarter using the CoA, the NegAA (Negative Action Agent) responds accordingly by executing a DLT with the transaction link and block ID provided. In this execution, the PAA (Positive Action Agent) and NeuAA (Neutral Action Agent) are uninvolved because the model classifies the user input as a negative statement.
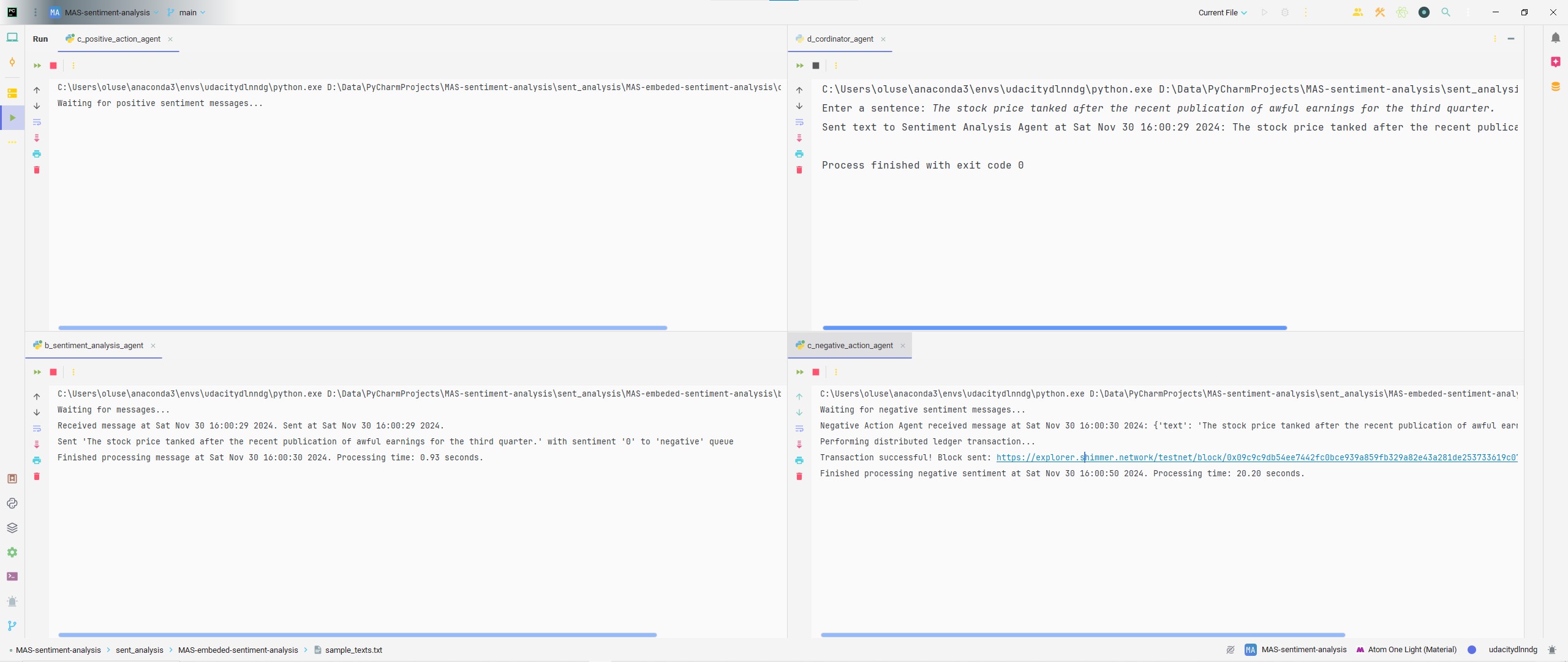
import json import time from a_connection import get_rabbitmq_connection from iota_env.simple_transaction import perform_transaction # Import the transaction function def callback(ch, method, properties, body): start_time = time.time() message = json.loads(body) text = message.get('text', '') sentiment = message.get('sentiment', None) print(f"Negative Action Agent received message at {time.ctime(start_time)}: {message}") if sentiment == 0: print("Performing distributed ledger transaction...") perform_transaction() # Call the imported transaction function end_time = time.time() print(f"Finished processing negative sentiment at {time.ctime(end_time)}. Processing time: {end_time - start_time:.2f} seconds.") def main(): try: # Setup RabbitMQ connection connection = get_rabbitmq_connection() channel = connection.channel() # Declare the exchange and queue channel.exchange_declare(exchange='sentiment_exchange', exchange_type='direct') channel.queue_declare(queue='negative_queue') # Bind the queue to the exchange with the "negative" routing key channel.queue_bind(exchange='sentiment_exchange', queue='negative_queue', routing_key='negative') # Start consuming messages channel.basic_consume(queue='negative_queue', on_message_callback=callback, auto_ack=True) print("Waiting for negative sentiment messages...") channel.start_consuming() except Exception as e: print(f"Error with RabbitMQ connection or consumption: {e}") if __name__ == '__main__': main()
The webpage for the transaction is provided in the Figure below.
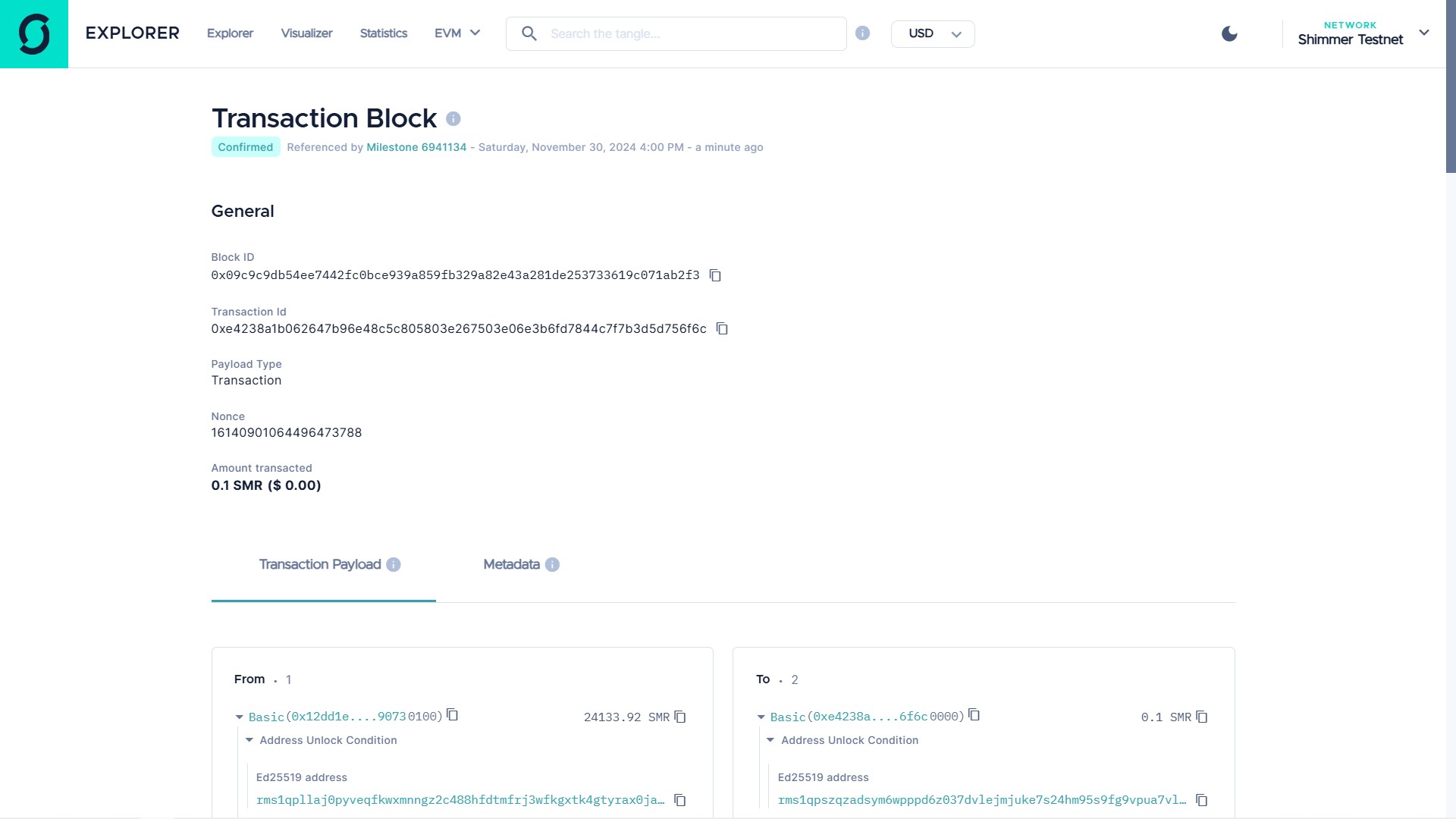
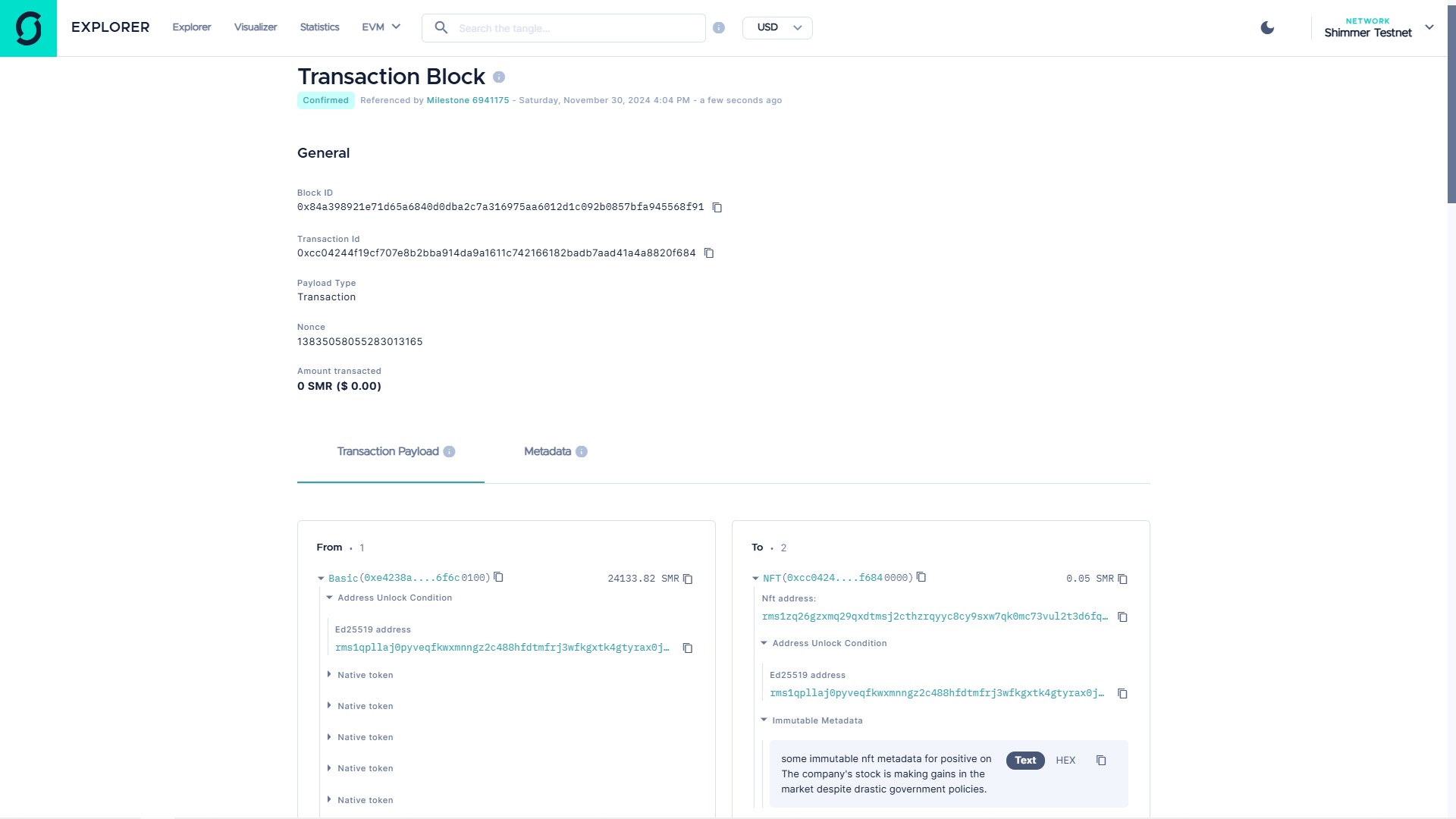
With the input The company's stock is making gains in the market despite drastic government policies. using the CoA, the PAA responds accordingly by minting an NFT based on the sentiment predicted by the SAA and the text provided by the user with the transaction link and block ID provided. In this execution, the NegAA and NeuAA are uninvolved because the model classifies this user input as positive.
import json import time from a_connection import get_rabbitmq_connection from iota_env.mint_nft import mint_nft # Import the updated mint_nft function def callback(ch, method, properties, body): start_time = time.time() message = json.loads(body) text = message.get('text', '') sentiment = message.get('sentiment', None) print(f"Positive Action Agent received message at {time.ctime(start_time)}: {message}") if sentiment == 2: print("Minting an NFT for the positive sentiment...") mint_nft("positive", text) # Pass the sentiment and text to mint_nft end_time = time.time() print(f"Finished processing positive sentiment at {time.ctime(end_time)}. Processing time: {end_time - start_time:.2f} seconds.") def main(): try: # Setup RabbitMQ connection connection = get_rabbitmq_connection() channel = connection.channel() # Declare the exchange and queue channel.exchange_declare(exchange='sentiment_exchange', exchange_type='direct') channel.queue_declare(queue='positive_queue') # Bind the queue to the exchange with the "positive" routing key channel.queue_bind(exchange='sentiment_exchange', queue='positive_queue', routing_key='positive') # Start consuming messages channel.basic_consume(queue='positive_queue', on_message_callback=callback, auto_ack=True) print("Waiting for positive sentiment messages...") channel.start_consuming() except Exception as e: print(f"Error with RabbitMQ connection or consumption: {e}") if __name__ == '__main__': main()
The webpage for the transaction is provided below.
Discussion
The MAS can be assessed in terms of scalability, communication latency and message handling.
In terms of scalability, which measures the system’s ability to maintain performance as the workload (e.g., number of agents or volume of messages) increases, the MAS does well with the messages we send starting from the coordinator agent passing through the sentiment analysis agent right to the appropriate action agents. With the application of a routing technique, the MAS can take in more agents that can handle more tasks as required.
As regards communication latency, which is the time taken for messages to be transmitted between agents via RabbitMQ. Our MAS system takes less than a second to receive messages between agents. This is a good sign that our system is standard.
The message handling capacity of a MAS measures the volume of messages RabbitMQ can process and route within a given timeframe. The CoA of this system is made to handle just an input/message. Nevertheless, using it several times will give an adequate response from the other agents. Hence, the system handles several messages perfectly.
There is no use in building a MAS for sentiment analysis if the classification model performs below expectations. Using the models with good accuracy i.e. LR or LSTM2 as shown in Figure 5.1, we are able to achieve a MAS for financial sentiment analysis. Hence, we achieved the third objective of this research.
Incorporating the distributed ledger transactions as part of our action agents (PAA and NegAA), we were able to show that the MAS system can be scaled with several agents that can perform different actions as intended. In a financial sense, this answers the third and fourth objectives of this research. The potential of this solution is wide-ranging. It can be applied across several industries such as finance, blockchain, governance, healthcare, and customer service amongst others who desire to build systems that respond to natural language in the form of text data. With the presence of state-of-the-art models and text preprocessing techniques, there is a possibility of building models that are capable of achieving close to 100% accuracy in classifying sentiments on texts irrespective of the domain involved. Hence, one could be well assured and let agents perform actions based on sentiments without much to little oversights.
Conclusion
This research was aimed at the development of a scalable MAS for financial sentiment analysis using RabbitMQ. The dataset used was culled from the work of Malo et al. (2014) [37]. The dataset comprised sentiments for financial news headlines from the perspective of a retail investor. The sentiments in the dataset for different news headlines are positive, negative and neutral. Because of the imbalance in the dataset, data augmentation was performed using an LLM in order to avoid bias in the models.
Utilizing RabbitMQ, we built a multi-agent system that is primarily based on the best model trained. The system gets input as (financial) text, preprocess it, and predicts the sentiment of the text and takes action(s) based on the outcome. With this, we build a system of five (5) agents. They are: 1) Coordinator agent (CoA), 2) Sentiment Analysis Agent (SAA), 3) Positive Action Agent (PAA), 4) Negative Action Agent (NegAA), and 5) Neutral Action Agent (NeuAA). In the context of this research, the NeuAA was considered trivial.
The CoA gives a user access to the system. It is through it that inputs are to be passed. The SAA does the simple job of preprocessing text inputs and predicting the sentiments on them. The two key action agents, i.e. NegAA and PAA perform actions based on the feedback from the SAA. The PAA mints an NFT based on the input using a DLT while the NegAA performs a ledger transaction by sending some funds to a wallet. These actions are based on the IOTA test net. The MAS is coordinated using RabbitMQ and the analysis of the system detailed that it is scalable, has low latency and handles messages quite well. In our experiments, messages get delivered between agents in a fraction of second. As a result, more agents can be added to the system with the assurance that there will be no problem with an overload or high latency.
The implementation of this research is available at https://github.com/olusegunajibola/MAS-sentiment-analysis.
References
[1] Junaid Akhtar. “An Interactive Multi-Agent Reasoning Model for Sentiment Analysis: A Case for Computational Semiotics”. In: Artificial Intelligence Review
53.6 (2020), pp. 3987–4004.
[2] Ateret Anaby-Tavor et al. “Do not have enough data? Deep learning to the rescue!” In: Proceedings of the AAAI conference on artificial intelligence. Vol. 34. 05. 2020, pp. 7383–7390.
[3] A. Anwar et al. “Emotions Matter: A Systematic Review and Meta-Analysis of the Detection and Classification of Students’ Emotions in STEM During Online Learning”. In: Education Sciences 13.9 (2023), p. 914.
[4] M. N. Ashtiani and B. Raahemi. “News-based Intelligent Prediction of Finan- cial Markets Using Text Mining and Machine Learning: A Systematic Litera- ture Review”. In: Expert Systems with Applications 217 (2023), p. 119509.
[5] Parasumanna Gokulan Balaji and Dipti Srinivasan. “An Introduction to Multi- Agent Systems”. In: Innovations in Multi-Agent Systems and Applications-1. Springer, 2010, pp. 1–27.
[6] W. Bian et al. “Emotional Text Analysis Based on Ensemble Learning of Three Different Classification Algorithms”. In: Proceedings of the 2019 IEEE 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS). Vol. 2. Metz, France: IEEE, 2019, pp. 938–941.
[7] Steven Bird, Ewan Klein, and Edward Loper. Natural language processing with Python: analyzing text with the natural language toolkit. " O’Reilly Media, Inc.",
2009.
[8] Piotr Bojanowski et al. “Enriching word vectors with subword information”. In: Transactions of the association for computational linguistics 5 (2017), pp. 135– 146.
[9] A. Bozanta et al. “Sentiment Analysis of StockTwits Using Transformer Mod- els”. In: 2021 20th IEEE International Conference on Machine Learning and Appli- cations (ICMLA). IEEE, 2021, pp. 1253–1258.
[10] Ovidiu Calin. Deep learning architectures. Springer, 2020.
[11] Hannah Chen, Yangfeng Ji, and David Evans. “Finding Friends and Flipping Frenemies: Automatic Paraphrase Dataset Augmentation Using Graph The- ory”. In: Findings of the Association for Computational Linguistics: EMNLP 2020. Ed. by Trevor Cohn, Yulan He, and Yang Liu. Online: Association for Com- putational Linguistics, Nov. 2020, pp. 4741–4751. DOI: 10 . 18653 / v1 / 2020 . findings - emnlp . 426. URL: https : / / aclanthology . org / 2020 . findings - emnlp.426.
[12] Yining Chen et al. “Scalable and Transferable Reinforcement Learning for Multi- Agent Mixed Cooperative–Competitive Environments Based on Hierarchical Graph Attention”. In: Entropy 24.4 (2022), p. 563.
[13] D Manning Christopher, Raghavan Prabhakar, and Schutze Hinrich. Introduc- tion to information retrieval. 2008.
[14] Marian Pompiliu Cristescu et al. “Analyzing the Impact of Financial News Sentiments on Stock Prices—A Wavelet Correlation”. In: Mathematics 11.23 (2023), p. 4830.
[15] Datareportal. Global Digital Overview. Accessed: 2024-09-19. 2024. URL: https: / / datareportal . com / global - digital - overview# : ~ : text = The % 20vast % 20majority%20of%20the, of%20the%20world’ s%20web%20traffic. .
[16] Giovanni De Gasperis, Sante Dino Facchini, and Ivan Letteri. “Leveraging Multi-Agent Systems and Decentralised Autonomous Organisations for Tax Credit Tracking: A Case Study of the Superbonus 110% in Italy”. In: Applied Sciences 14.22 (2024), p. 10622.
[17] Cem Dilmegani and Ezgi Alp. 6 Approaches for Sentiment Analysis Machine Learn- ing. https : / / research . aimultiple . com / sentiment - analysis - machine - learning / #real - life - examples - of - machine - learning - in - sentiment - analysis. Accessed: 2024-10-02. 2023.
[18] V. Dogra et al. “Analyzing DistilBERT for Sentiment Classification of Bank- ing Financial News”. In: Intelligent Computing and Innovation on Data Science: Proceedings of ICTIDS 2021. Springer Singapore, 2021, pp. 501–510.
[19] A. Dorri, S. S. Kanhere, and R. Jurdak. “Multi-Agent Systems: A Survey”. In: IEEE Access 6 (2018), pp. 28573–28593.
[20] S. A. Farimani et al. “Investigating the Informativeness of Technical Indica- tors and News Sentiment in Financial Market Price Prediction”. In: Knowledge- Based Systems 247 (2022), p. 108742.
[21] Steven Y. Feng et al. “A Survey of Data Augmentation Approaches for NLP”. In: Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Online: Association for Computational Linguistics, Aug. 2021, pp. 968–988. DOI: 10 . 18653 / v1 / 2021 . findings - acl . 84. URL: https : / / aclanthology . org/2021.findings- acl.84.
[22] M. Gatti et al. “Large-Scale Multi-Agent-Based Modeling and Simulation of Microblogging-Based Online Social Network”. In: Multi-Agent-Based Simula- tion XIV: International Workshop, MABS 2013, Saint Paul, MN, USA, May 6-7, 2013, Revised Selected Papers. Springer Berlin Heidelberg, 2014, pp. 17–33.
[23] Hannes Hapke, Cole Howard, and Hobson Lane. Natural Language Processing in Action: Understanding, Analyzing, and Generating Text with Python. Simon and Schuster, 2019.
[24] J. Z. G. Hiew et al. “BERT-Based Financial Sentiment Index and LSTM-Based Stock Return Predictability”. In: arXiv preprint arXiv
.09024 (2019).[25] Geoffrey Hinton. “Distilling the Knowledge in a Neural Network”. In: arXiv preprint arXiv
.02531 (2015).[26] S Hochreiter. “Long Short-term Memory”. In: Neural Computation MIT-Press (1997).
[27] Gareth James. An introduction to statistical learning. 2013. [28] Daniel Jurafsky. Speech and language processing. 2000.
[29] Dhvani Kansara and Vinaya Sawant. “Comparison of Traditional Machine Learning and Deep Learning Approaches for Sentiment Analysis”. In: Algo- rithms for Intelligent Systems. Accessed: 2024-10-02. Springer Nature, 2020, pp. 365– 377. DOI: 10.1007/978- 981- 15- 3242- 9_35.
[30] Chetan Kaushik and Atul Mishra. “A Scalable, Lexicon Based Technique for Sentiment Analysis”. In: arXiv preprint arXiv
.2265 (2014).[31] Ron Kohavi. “Glossary of terms”. In: Machine learning 30 (1998), pp. 271–274. [32] Jan Ole Krugmann and Jochen Hartmann. “Sentiment Analysis in the Age of
Generative AI”. In: Customer Needs and Solutions 11.1 (2024). Accessed: 2024- 10-02. DOI: 10.1007/s40547- 024- 00143- 4.
[33] Miroslav Kubat, Robert C Holte, and Stan Matwin. “Machine learning for the detection of oil spills in satellite radar images”. In: Machine learning 30 (1998), pp. 195–215.
[34] Akshay Kulkarni and Adarsha Shivananda. Natural language processing recipes. Springer, 2019.
[35] Jun Li, Yuchen Zhu, and Kexue Sun. “A novel iteration scheme with conjugate gradient for faster pruning on transformer models”. In: Complex & Intelligent Systems 10.6 (2024), pp. 7863–7875.
[36] Ruibo Liu et al. “Data boost: Text data augmentation through reinforcement learning guided conditional generation”. In: arXiv preprint arXiv
.02952 (2020).[37] P. Malo et al. “Good Debt or Bad Debt: Detecting Semantic Orientations in Eco- nomic Texts”. In: Journal of the Association for Information Science and Technology 65.4 (2014), pp. 782–796.
[38] Sheri M. Markose. “Systemic Risk Analytics: A Data-Driven Multi-Agent Financial Network (MAFN) Approach”. In: Journal of Banking Regulation 14 (2013), pp. 285–305.
[39] Tomas Mikolov. “Efficient estimation of word representations in vector space”. In: arXiv preprint arXiv
.3781 3781 (2013).[40] Joshua J. Myers. Sentiment Analysis Revisited. Accessed: 2024-10-01. 2023. URL:
https : / / blogs . cfainstitute . org / investor / 2023 / 11 / 01 / sentiment - analysis- revisited/.
[41] H.Q. Nguyen and Q.U. Nguyen. “An Ensemble of Shallow and Deep Learn- ing Algorithms for Vietnamese Sentiment Analysis”. In: Proceedings of the 2018 IEEE 5th NAFOSTED Conference on Information and Computer Science (NICS). Ho Chi Minh City, Vietnam: IEEE, 2018, pp. 165–170.
[42] Jasmina Dj Novakovi´c et al. “Evaluation of classification models in machine learning”. In: Theory and Applications of Mathematics & Computer Science 7.1 (2017), p. 39.
[43] Federico Pascual. Getting Started with Sentiment Analysis using Python. https : / / huggingface . co / blog / sentiment - analysis - python . Accessed: 2024-10- 02. 2022.
[44] Rajvardhan Patil et al. “A survey of text representation and embedding tech- niques in nlp”. In: IEEE Access 11 (2023), pp. 36120–36146.
[45] Jeffrey Pennington, Richard Socher, and Christopher D Manning. “Glove: Global vectors for word representation”. In: Proceedings of the 2014 conference on empir- ical methods in natural language processing (EMNLP). 2014, pp. 1532–1543.
[46] Husam Quteineh, Spyridon Samothrakis, and Richard Sutcliffe. “Textual data augmentation for efficient active learning on tiny datasets”. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020, pp. 7400–7410.
[47] Sebastian Raschka. “Model evaluation, model selection, and algorithm selec- tion in machine learning”. In: arXiv preprint arXiv
.12808 (2018).[48] Gözde Gül ¸Sahin and Mark Steedman. “Data Augmentation via Dependency Tree Morphing for Low-Resource Languages”. In: Proceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing. Ed. by Ellen Riloff et al. Brussels, Belgium: Association for Computational Linguistics, 2018, pp. 5004– 5009. DOI: 10 . 18653 / v1 / D18 - 1545. URL: https : / / aclanthology . org / D18 - 1545.
[49] C. Sahoo, M. Wankhade, and B.K. Singh. “Sentiment Analysis Using Deep Learning Techniques: A Comprehensive Review”. In: International Journal of Multimedia Information Retrieval 12 (2023), p. 41. DOI: 10 . 1007 / s13735 - 023 - 00308- 2.
[50] Victor Sanh et al. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter”. In: NeurIPS EMC2 Workshop. 2019.
[51] Rico Sennrich. “Improving neural machine translation models with monolin- gual data”. In: arXiv preprint arXiv
.06709 (2015).[52] Sentiment Analysis: Definition, Importance, Indicator Types, Benefits. https : / / www . strike . money / technical - analysis / sentiment - analysis . Accessed: 2024-10-01. 2023.
[53] Neeraj Anand Sharma, A. B. M. Shawkat Ali, and Muhammad Ashad Kabir. “A Review of Sentiment Analysis: Tasks, Applications, and Deep Learning Techniques”. In: International Journal of Data Science and Analytics (2024). DOI: 10.1007/s41060- 024- 00594- x.
[54] T. Sharvari and K. Sowmya Nag. “A Study on Modern Messaging Systems - Kafka, RabbitMQ and NATS Streaming”. In: CoRR abs/1912.03715 (2019).
[55] Skymind. A Beginner’s Guide to LSTMs and Recurrent Neural Networks. https : //web.archive.org/web/20190106151528/https://skymind.ai/wiki/lstm . Accessed: 2024-11-09. 2019.
[56] Kian Long Tan, Chin Poo Lee, and Kian Ming Lim. “A Survey of Sentiment Analysis: Approaches, Datasets, and Future Research”. In: Applied Sciences 13.7 (2023), p. 4550.
[57] A Vaswani. “Attention is all you need”. In: Advances in Neural Information Pro- cessing Systems (2017).
[58] M. Wankhade, A. C. S. Rao, and C. Kulkarni. “A Survey on Sentiment Analysis Methods, Applications, and Challenges”. In: Artificial Intelligence Review 55.7 (2022), pp. 5731–5780.
[59] Jason Wei and Kai Zou. “Eda: Easy data augmentation techniques for boosting performance on text classification tasks”. In: arXiv preprint arXiv
.11196 (2019).[60] What Is Sentiment Analysis? What Are the Different Types? https : / / builtin . com/machine- learning/sentiment- analysis. Accessed: 2024-10-02. 2023.
[61] Jason Williams. RabbitMQ in Action: Distributed Messaging for Everyone. Simon and Schuster, 2012
[62] World Economic Forum. “Charted: There are more mobile phones than people in the world”. In: (2023). Accessed: 2024-09-19. URL: https : / / www . weforum . org / agenda / 2023 / 04 / charted - there - are - more - phones - than - people - in - the- world/.
[63] Yong Yu et al. “A review of recurrent neural networks: LSTM cells and net- work architectures”. In: Neural computation 31.7 (2019), pp. 1235–1270.
[64] Sangdoo Yun et al. “Cutmix: Regularization strategy to train strong classifiers with localizable features”. In: Proceedings of the IEEE/CVF international confer- ence on computer vision. 2019, pp. 6023–6032.
[65] Hongyi Zhang. “mixup: Beyond empirical risk minimization”. In: arXiv preprint arXiv
.09412 (2017).Acknowledgements
This project was carried out as a part of the requirement in fulfilment of the achievement of a master's degree in Applied Data Science at the Department of Engineering and Computer Science and Mathematics (DISIM) of the University of L'Aquila under the supervision of Prof. Giovanni De Gasperis.