Abstract
Using Paligemma for deepfake image classification
- Fine-tune Paligemma with deepfake image dataset
- Using QLoRa for memory efficiency
- After training for 10 epochs, accuracy measured on 1,000 images: 94.80
- Label distribution: {0: 541, 1: 459}
This Project GitHub is here!
https://github.com/bdg9412/Paligemma_deepfake_classification
Introduction
Recently, there has been a significant increase in reports about deepfake-related crimes in the news. Similar to the ongoing nature of cyberattacks, I believe that measures to detect deepfakes should be diversified and rapidly supplied to the market. As a solution to this issue, I intend to leverage generative AI for detecting deepfake images. Specifically, I aim to fine-tune a multimodal model to infer whether an image is generated by receiving both deepfake image and text as inputs.
The foundation of this idea comes from the relationship between black hat hackers and white hat hackers. Just as security teams and hackers understand each other's perspectives to counteract threats, I thought a generative AI fine-tuned with relevant knowledge about deepfake crimes might better understand and detect them. For this project, I chose a model capable of analyzing both images and text, such as Paligemma.
Methodology
Model
- Selected a multimodal model from the Gemma family capable of taking both image and text as input.
- Used google/paligemma-3b-pt-224
- training on Colab / L4
Dataset
- Deepfake image dataset from huggingface
Data Processing
- Generated the question column manually.
- Simple questions: step loss [0.135400]
- Questions with additional information: step loss [0.118300]
- Adding simple additional information to the question column reduced step loss but resulted in a decline in classification performance.
- Verified from the MM-CoT paper that approaches adding CoT to LLMs did not enhance performance.
- Inspired by the MM-CoT paper's use of image features, added image captioning information to the model's input.
- Confirmed that increasing the r value in QLoRa enhances expressiveness and identified the need to revise the prompt design.
- Observed that step loss significantly varied, from 0.186500 to 0.136900, depending on the prompt design.
- more accuracy than simple additional information
Train
The Paligemma base model used for training includes areas similar to the deepfake image dataset selected from Hugging Face. Therefore, parameter updates for image encoder areas were not performed, and training was configured to focus on other parts.
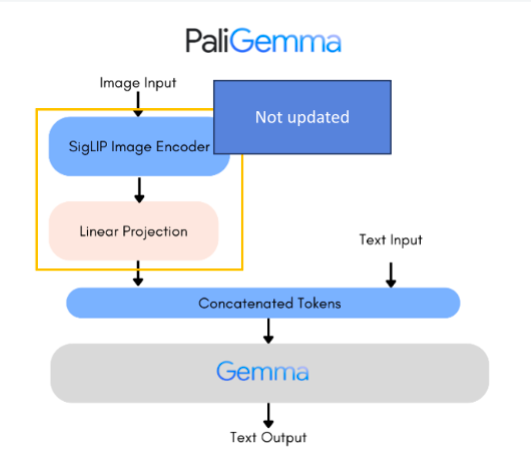
Results
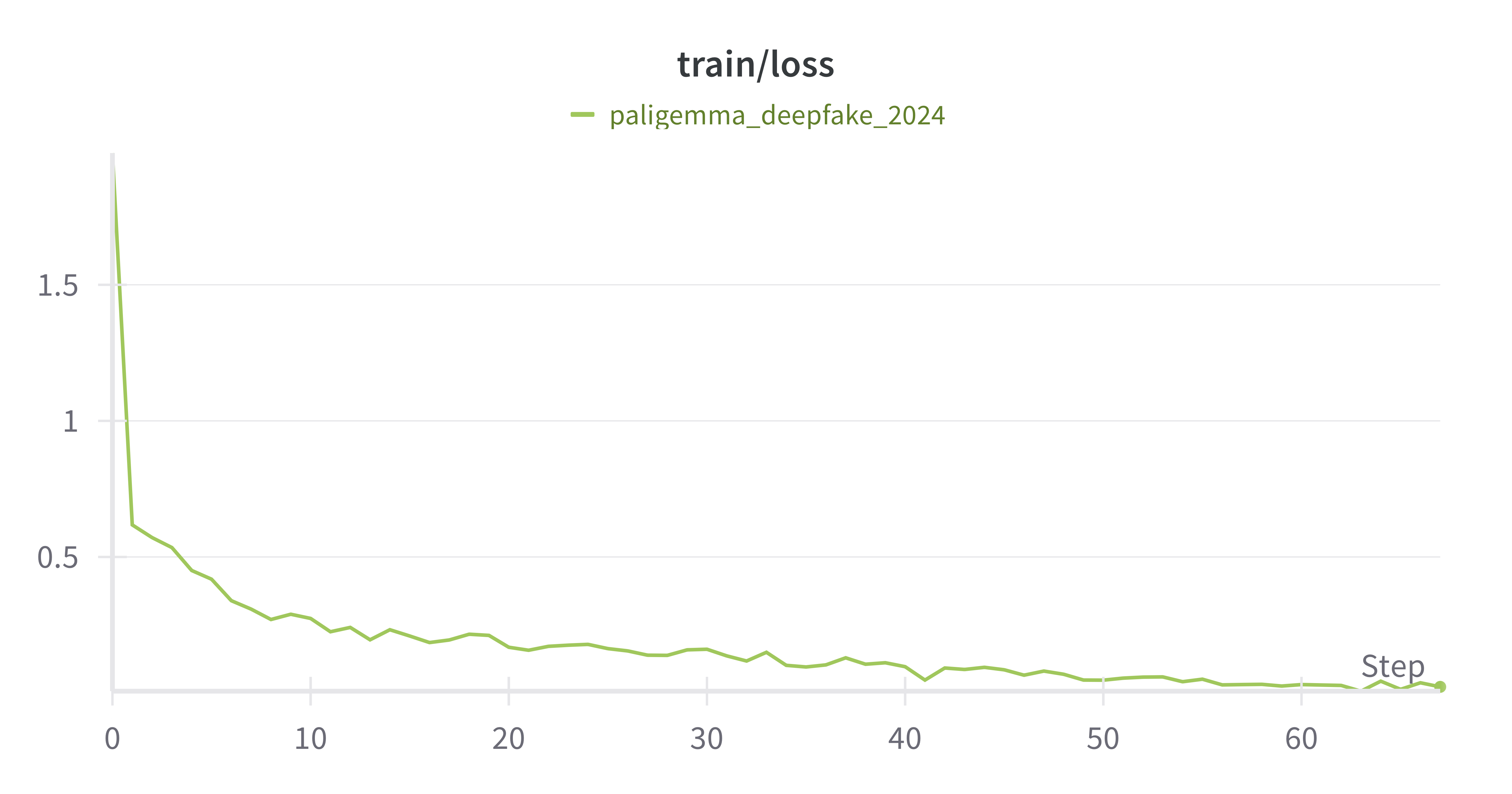
Train 10 epoch Loss
Check model’s accuracy with unseen datasets
# Inference true_labels = [] predicted_labels = [] image_token = processor.tokenizer.convert_tokens_to_ids("<image>") bos_token = processor.tokenizer.bos_token # BOS 토큰 가져오기 for arg in tqdm(range(len(ds['validation']['label']))[19100:20100]): image_x = ds['validation'][arg]['image'] label_y = ds['validation'][arg]['label'] true_labels.append(label_y) prompt = f"<image> {bos_token} answer Is this image made by AI?" image_file = image_x.convert("RGB") inputs = processor(prompt, image_file, return_tensors="pt", padding="longest") output = model.generate(**inputs, max_new_tokens=20) pdredict_x = processor.decode(output[0], skip_special_tokens=True)[-1:] predicted_labels.append(int(predict_x))
# Calculate accuracy score accuracy = accuracy_score(true_labels, predicted_labels) print(f"정확도: {accuracy * 100:.2f}%")
정확도: 98.40%
Conclusion
We have planned the fine-tuning of generative AI models to enable automation in deepfake image detection tasks. Through this approach, we aim to contribute to addressing the demand for increased personnel to combat deepfake-related crimes.
Thank you, Ai factory, Ready Tensor and Google developer program, for showing interest in my project.