In the age of information overload, finding the perfect movie to watch can be a daunting
task. This project presents a sophisticated movie recommendation system that leverages Natural Language Processing (NLP) and machine learning techniques to enhance user experience by providing tailored movie suggestions. Our system offers users three distinct options to input their preferences: keywords/genres, language, or movie title. By
selecting any of these options, users receive personalized movie recommendations
based on their choice.
The core of our recommendation engine is built upon Google's Universal Sentence
Encoder, a powerful tool that captures the semantic meaning of textual data. This
enables our system to understand and interpret the nuances of user inputs effectively. To generate accurate recommendations, we employ the Nearest Neighbors (NN) algorithm, which identifies up to ten movies that closely match the user's specified criteria.
By integrating advanced NLP techniques and machine learning algorithms, our movie
recommendation system not only enhances the relevance of suggestions but also offers
a seamless and intuitive user experience. This project demonstrates the potential of
combining state-of-the-art language models with robust machine learning methods to
solve real-world problems in the entertainment industry.
In today's digital age, the sheer volume of available movies presents a significant
challenge for viewers attempting to find films that match their preferences. Traditional
recommendation systems, often based on collaborative filtering or simple content-based approaches, can fall short in delivering personalized and contextually relevant
suggestions. To address these limitations, we propose a sophisticated movie recommendation system that leverages Natural Language Processing (NLP) and machine learning techniques to provide users with highly tailored movie suggestions.
Our system is designed to accommodate various user preferences through three input
options: keywords/genres, language, and movie title. By selecting one of these options,
users can easily convey their interests, enabling the system to generate customized
recommendations. The backbone of our recommendation engine is Google's Universal
Sentence Encoder, a state-of-the-art NLP model that captures the semantic meaning of
textual inputs, allowing for a deep understanding of user queries.
To identify the most relevant movies, we employ the Nearest Neighbors (NN) algorithm, which evaluates the proximity of movie features based on the user's input. This method ensures that the recommendations are not only accurate but also diverse, enhancing the
user's viewing experience.
This project aims to demonstrate the effectiveness of combining advanced NLP models with machine learning algorithms in creating a movie recommendation system that is both intuitive and highly responsive to user preferences. By addressing the shortcomings of existing recommendation systems, our approach offers a significant improvement in delivering personalized content, ultimately enriching the user's interaction with digital entertainment platforms.
RESEARCH DESIGN
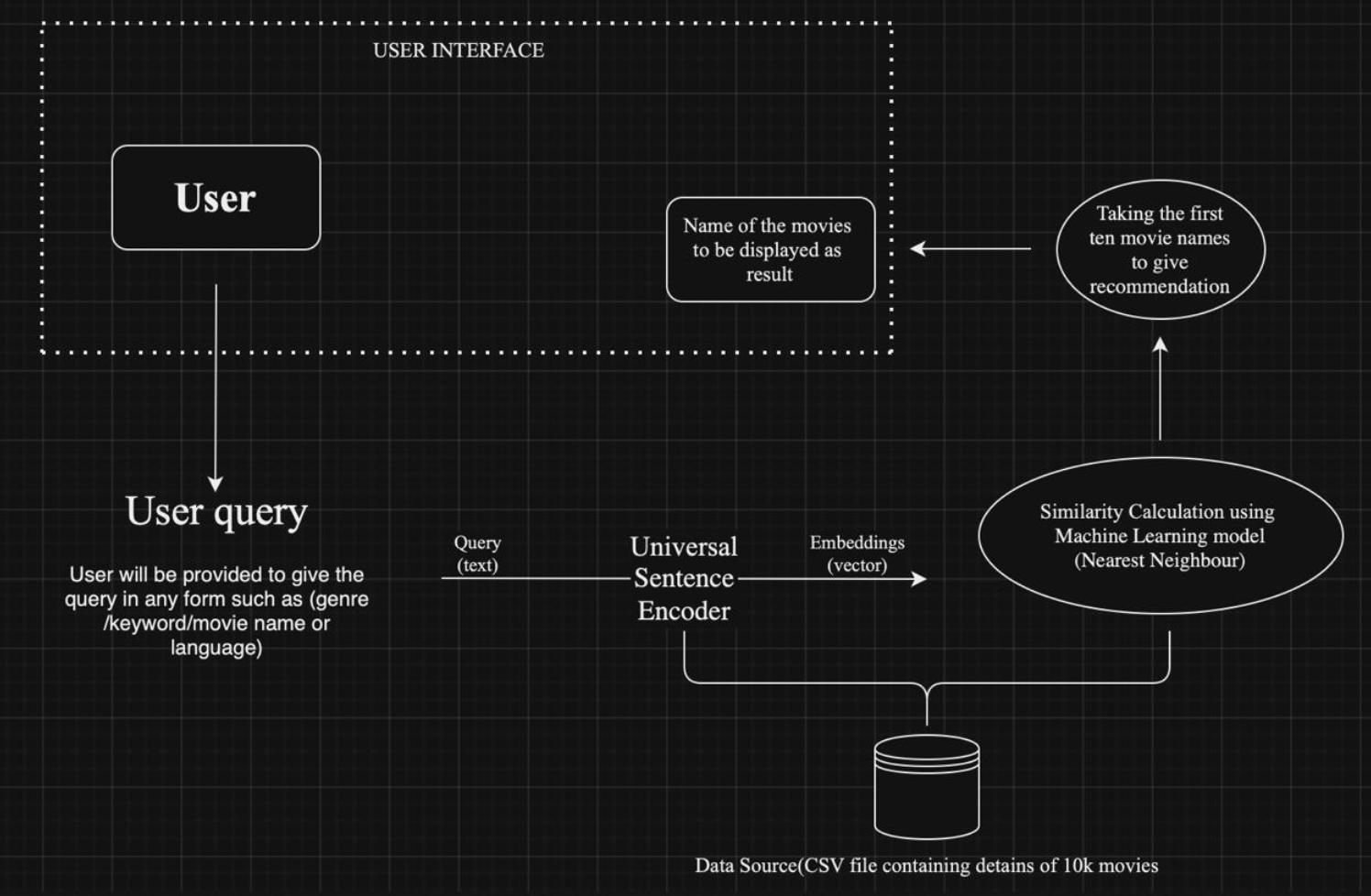
The movie recommendation system is designed to suggest movies based on user queries.
Users can input their queries in various forms such as genre, keywords, movie names, or
language. The system processes these queries and returns a list of recommended movies
by leveraging machine learning techniques.
Components:-
User Interface
• User: The end-user who interacts with the system through the user interface,
providing queries to receive movie recommendations.
• User Query: The input provided by the user, which can be in the form of a genre,
keyword, movie name, or language.
Backend Processing
• Universal Sentence Encoder (USE)
The user query, which is in text form, is sent to the Universal Sentence Encoder.
The USE transforms the text query into embeddings (vectors). These embeddings
capture the semantic meaning of the query, allowing the system to understand and
process the user's intent.
Data Source
• CSV File: A data source containing details of 10,000 movies, including their
features and attributes, is used. This file is crucial for the recommendation
process, as it provides the necessary information to compare against the user
query.
Machine Learning Model
• Similarity Calculation:
The embeddings generated by the USE are fed into a similarity calculation
module. The similarity calculation is performed using a Machine Learning model,
specifically the Nearest Neighbour algorithm. This algorithm identifies movies in
the dataset that are most similar to the user's query based on the vector
embeddings.
• Top Ten Recommendations:
The model ranks the movies based on their similarity to the user query. The top
most similar movie names are selected as recommendations.
Output
• Recommendation Results:
The names of the top ten recommended movies are displayed to the user through the user
interface.
Universal Sentence Encoder:
The Universal Sentence Encoder (USE) is a pre-trained model developed by Google for
encoding text into high-dimensional vectors that capture the semantic meaning of the
text. These vectors can then be used for various natural language processing tasks, such as text classification, clustering, and semantic similarity analysis. The encoder is designed to handle sentences, phrases, and even paragraphs, and it produces fixed-length vectors regardless of the input length. USE models are built using deep learning techniques and trained on a large corpus of diverse text data. They provide robust, versatile embeddings that can be easily integrated into downstream machine learning models, facilitating improved performance in NLP applications.
Nearest Neighbor:
Nearest Neighbors is a machine learning algorithm used for classification, regression,
and recommendation systems. It operates on the principle that similar data points exist
in close proximity within the feature space. The algorithm identifies the "neighbors" (i.e.,
the closest data points) to a given query point based on a chosen distance metric, commonly Euclidean distance.
• Feature Extraction and Embeddings: By converting movie descriptions, titles, and
languages into embeddings, we ensure that each movie is represented in a way
that captures its semantic content.
• Nearest Neighbors Model: This model allows us to efficiently search through the
high-dimensional embedding space to find movies that are close to a given movie
based on their content.
• Recommendations: By querying the model with a movie that a user likes, we can
find and recommend other movies that are similar in content, thereby
personalizing the recommendation based on user preferences.
Creating three different embed functions:
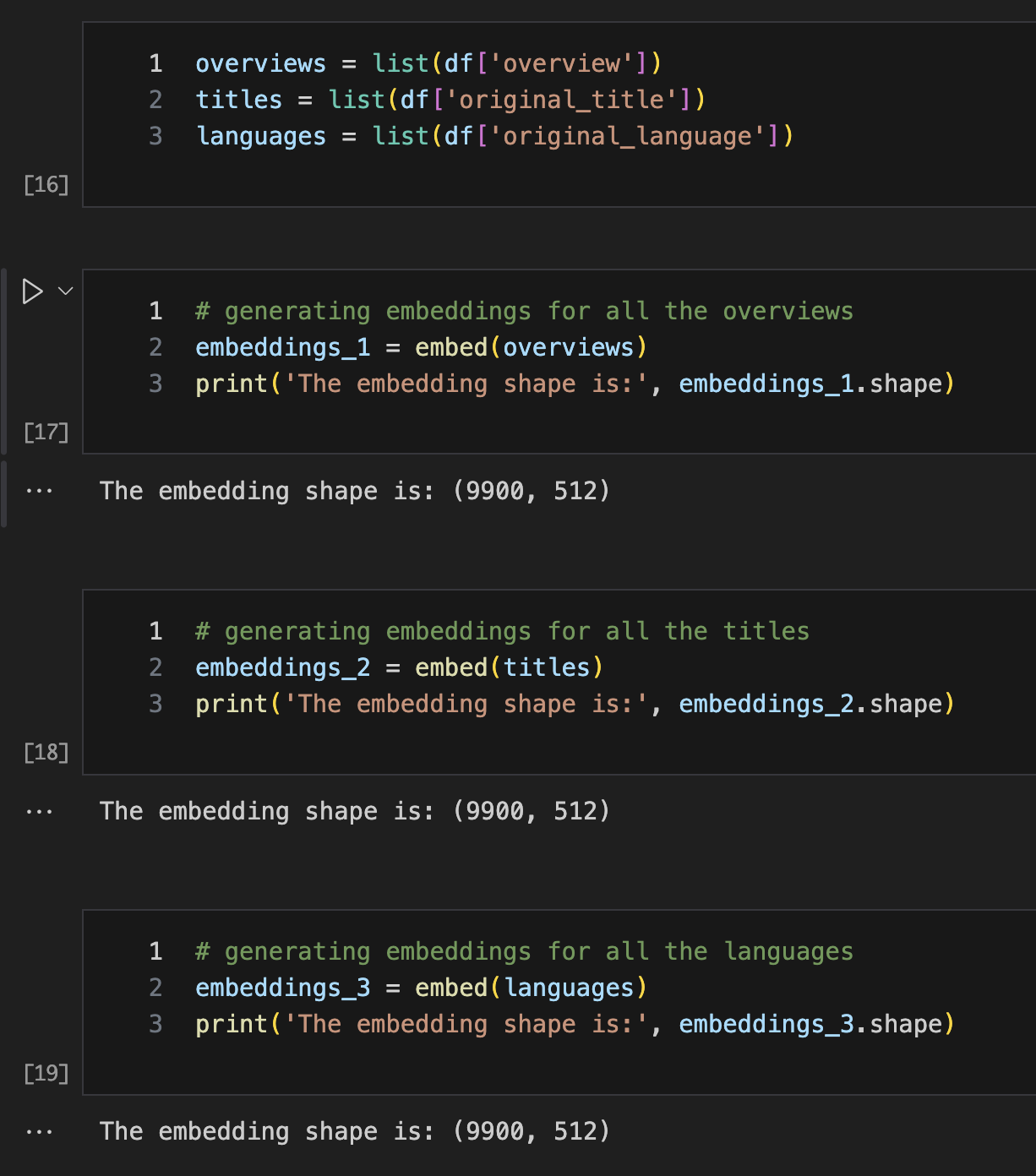
Extracts Features:
Creates lists of movie overviews, titles, and original languages from the Data
Frame.
Generates Embeddings:
Uses the Universal Sentence Encoder to generate 512-dimensional embeddings
for each of these features:
• embeddings_1 for overviews
• embeddings_2 for titles
• embeddings_3 for languages
3.Embedding Shapes:
Outputs the shape of each embedding tensor to confirm the number of embeddings
and their dimensionality.
1. Enhanced Understanding of NLP in Recommendation Systems:
• This project illustrates the power of advanced NLP techniques, such as the
Universal Sentence Encoder, in capturing the semantic meaning of textual data. It
underscores the importance of leveraging pre-trained language models to improve
the accuracy and relevance of recommendations in data science applications.
2. Integration of Multi-Feature Data:
• By incorporating various features like movie overviews, titles, and languages, the
project demonstrates the value of multi-feature data integration. This approach can
be applied to other domains where combining different types of data can lead to
more comprehensive and accurate models.
3. Importance of Data Preprocessing:
• The project emphasizes the critical role of data preprocessing and cleaning in
building reliable machine learning models.
• Handling missing values, normalizing data, and converting data types are essential
steps that can significantly impact model performance and accuracy.
4. Evaluation Metrics and Accuracy Measurement:
• The structured approach to evaluating the recommendation system using accuracy
and similarity measures provides a framework that can be adopted for assessing
other machine learning models. This highlights the importance of rigorous
evaluation metrics in validating model performance.
5. User-Centric Design in Data Science:
• The project’s focus on user inputs and customization demonstrates the
significance of user-centric design.
• Developing systems that can adapt to user preferences enhances user experience
and engagement, a principle that is widely applicable across various data science
applications.
PRACTICAL APPLICATIONS
Streaming Services:
• The movie recommendation system can be directly applied to streaming platforms
like Netflix, Amazon Prime, and Disney+, where personalized movie and show
recommendations are crucial for user retention and satisfaction.
E-Commerce:
• Similar techniques can be applied to recommend products in e-commerce
platforms like Amazon and eBay, enhancing the shopping experience by
suggesting products based on user preferences and past behaviour.
Content Platforms:
• Platforms like YouTube, Spotify, and Medium can use similar recommendation
systems to suggest videos, music, and articles, respectively, based on user
interests and interaction history.
Social Media:
• Social media platforms can utilize recommendation systems to suggest friends,
groups, or content that aligns with users' interests, thereby increasing engagement
and user activity.
Travel and Hospitality:
• Personalized travel recommendations, such as destinations, hotels, and activities,
can be provided based on user preferences and past travel history, enhancing user
experience in travel planning.
In conclusion, this movie recommendation project leverages advanced natural language
processing techniques and machine learning algorithms to provide personalized movie
recommendations based on user preferences. By utilizing the Universal Sentence Encoder to extract semantic representations of movie overviews, titles, and languages, the system effectively captures the essence of each movie's content. The Nearest Neighbors algorithm then facilitates the identification of similar movies in the embedding space, enabling tailored recommendations for users.
Through thorough data preprocessing, exploration, and modeling, the project has
successfully developed a robust recommendation system capable of delivering relevant movie suggestions across a diverse range of genres, titles, and languages. The evaluation metrics, including accuracy and similarity scores, provide quantitative measures of the system's performance, ensuring the reliability and effectiveness of the recommendations
provided.
Overall, this project showcases the potential of natural language processing and machine
learning techniques in building intelligent recommendation systems that enhance user
experiences and satisfaction. With further refinement and optimization, such systems
can be deployed in various applications, including streaming platforms, e-commerce
websites, and content recommendation engines, to deliver personalized
recommendations and improve user engagement.