This work focuses on the implementation of a YOLO (You Only Look Once) object detection model integrated into a self-driving car system for real-time object detection and response. The model is capable of identifying and locating objects such as pedestrians, cars, and motorcycles around the vehicle. By leveraging Intersection Over Union (IOU) and Non-Max Suppression (NMS) techniques, the system ensures accurate and precise bounding boxes to identify objects effectively.
IOU is employed to calculate the overlap between predicted bounding boxes and ground truth, facilitating better decision-making when multiple bounding boxes overlap. NMS further refines this process by retaining only the most relevant bounding boxes, ensuring optimal object detection. The detection probability is computed based on two factors: class identification using vector sum and distance estimation between the object and the car.
This system enables the self-driving car to adapt its speed or stop entirely upon detecting objects in its vicinity, ensuring safety and functionality. This integration demonstrates the effectiveness of advanced object detection methodologies in enhancing autonomous vehicle performance.
Introduction
In today’s rapidly evolving world, the demand for autonomous driving technology has surged as a solution to address critical challenges such as road safety, traffic congestion, and the environmental impact of traditional transportation systems. With millions of lives lost each year due to road accidents—many caused by human error—the urgency for developing self-driving cars has never been greater. Autonomous vehicles promise not only to reduce these fatalities but also to provide efficient and sustainable mobility solutions for an ever-growing urban population.
One of the most pressing challenges in this field is equipping autonomous systems with reliable object detection capabilities. For a self-driving car to navigate safely, it must accurately perceive and respond to its surroundings, identifying vehicles, pedestrians, and other obstacles in real-time. However, in unpredictable and dynamic environments, current object detection systems often face limitations in precision, adaptability, and efficiency. Misclassifications or missed detections can lead to catastrophic outcomes, highlighting the need for robust and scalable solutions.
This project addresses these challenges by building a sophisticated car detection system, utilizing cutting-edge machine learning techniques. A camera mounted on the hood of the vehicle captures continuous images of the road ahead, forming a dataset annotated with bounding boxes around objects of interest. The system is trained to detect up to 80 distinct classes, enabling it to recognize cars, pedestrians, motorcycles, and other critical road elements. Advanced algorithms such as YOLO (You Only Look Once), combined with techniques like Intersection Over Union (IOU) and Non-Max Suppression (NMS), ensure high precision in object detection while reducing errors caused by overlapping predictions.
By tackling the real-world issues of safety, adaptability, and efficiency, this project aims to contribute to the broader mission of autonomous driving. It seeks to empower vehicles with the intelligence needed to navigate complex scenarios, ultimately creating a safer and more reliable transportation future.
YOLO
"You Only Look Once" (YOLO) is a real-time object detection algorithm that processes an image in a single forward pass through the network. It outputs bounding boxes and associated class probabilities for detected objects. Post non-max suppression, the algorithm provides accurate predictions.
3.1 Model Details
Inputs and Outputs: The model takes a batch of images of shape (608, 608, 3) and outputs bounding boxes represented by 85 values, including class probabilities.
Anchor Boxes: Five pre-defined anchor boxes, based on training data, represent height/width ratios. The final encoding has a shape of (19, 19, 425).
Class Score
3.2 Filtering with a Threshold
Thresholding removes boxes with low class scores. The filtering process leverages box_confidence, boxes, and box_class_probs derived from the YOLO output to retain high-confidence predictions.
4 YOLO Encoding Overview
Preprocessed Input Image:
The input is an image of size (608, 608 ,3) representing a 608x608 RGB image with three color channels. This is standardized for compatibility with the YOLO architecture.
4.1 Deep CNN Feature Extraction:
The image passes through a convolutional neural network (CNN) that extracts feature maps. YOLO reduces spatial dimensions by a factor of 32, transforming the input into an encoding tensor of shape (19,19,5,85).
Formulas for Encoding:
The bounding box center coordinates (𝑏_x, 𝑏_𝑦) are calculated relative to the grid cell:
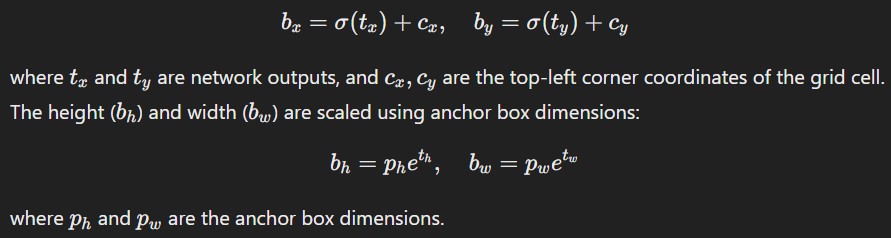
4.2 Bounding Box Representation
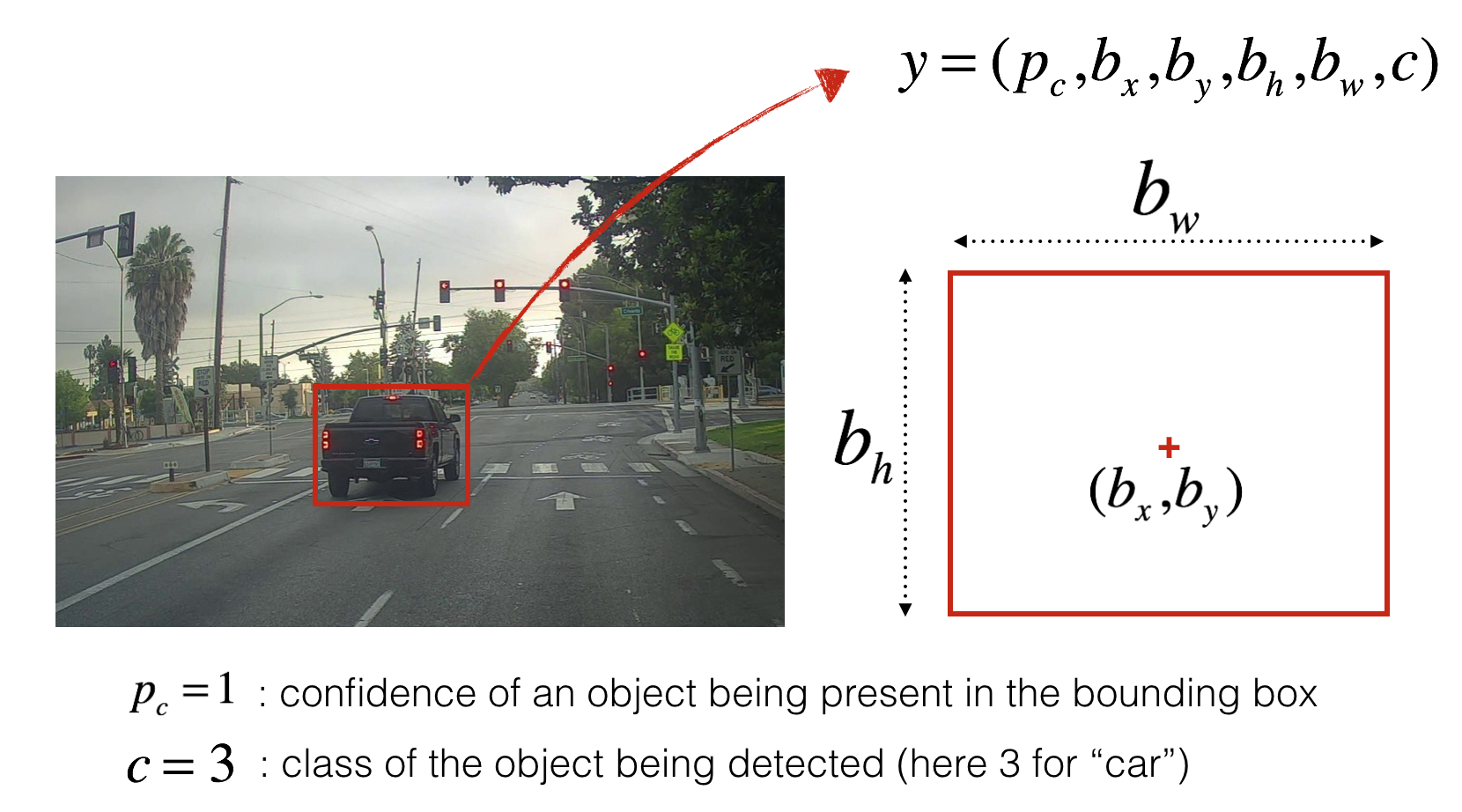
Bounding Box Parameters:
The bounding box is represented by (𝑝_𝑐, 𝑏_𝑥, 𝑏_𝑦, 𝑏_ℎ, 𝑏_𝑤, 𝑐)
p_c =1: Indicates high confidence for the presence of an object in the bounding box
c=3: Specifies the detected object's class (e.g., "car").
Visualization in the Grid:
The bounding box's center is defined by coordinates (𝑏_𝑥, 𝑏_𝑦) relative to the grid cell, and its dimensions (𝑏_ℎ, 𝑏_𝑤) are scaled to the image size.
Intersection over Union (IoU):
To refine predictions, YOLO uses IoU to compare predicted bounding boxes with ground truth:

Flattening the Dimensions for YOLO Encoding
In the YOLO model:
19x19x5x85):19x19x425). This creates a single tensor where all predictions for each grid cell are stored in a compact form.Intersection over Union (IoU)
IoU measures the overlap between two bounding boxes:
Intersection over Union (IoU)
Intersection over Union (IoU) is a metric used to evaluate the accuracy of object detection models by measuring the overlap between two bounding boxes: the predicted box and the ground truth box.
Formula:

Where:
Area of Intersection: The area where the predicted bounding box overlaps with the ground truth bounding box.
Area of Union: The total area covered by both the predicted and ground truth bounding boxes combined (union).
Interpretation:
IoU is used in Non-Maximum Suppression (NMS) to determine how closely two boxes match and whether one box should be discarded or not.
Steps in YOLO Non-Maximum Suppression:
Bounding Boxes and Confidence Scores: After the model predicts multiple bounding boxes, each one is assigned a confidence score (probability that an object is detected in the box).
IoU Thresholding: Compute the IoU between each pair of predicted bounding boxes. If the IoU between two boxes exceeds a certain threshold, they are considered to be detecting the same object.
Keep the Box with the Highest Confidence: If two boxes have a high overlap (high IoU) but different confidence scores, the box with the higher confidence score is retained, and the other is discarded.
Repeat: The process is repeated for all boxes. At the end, only the boxes with the highest confidence for unique objects are kept.
Formula:
For each predicted bounding box 𝐵_𝑖:

Key Metrics:



Insights of the model working and how it predicting through the grids:

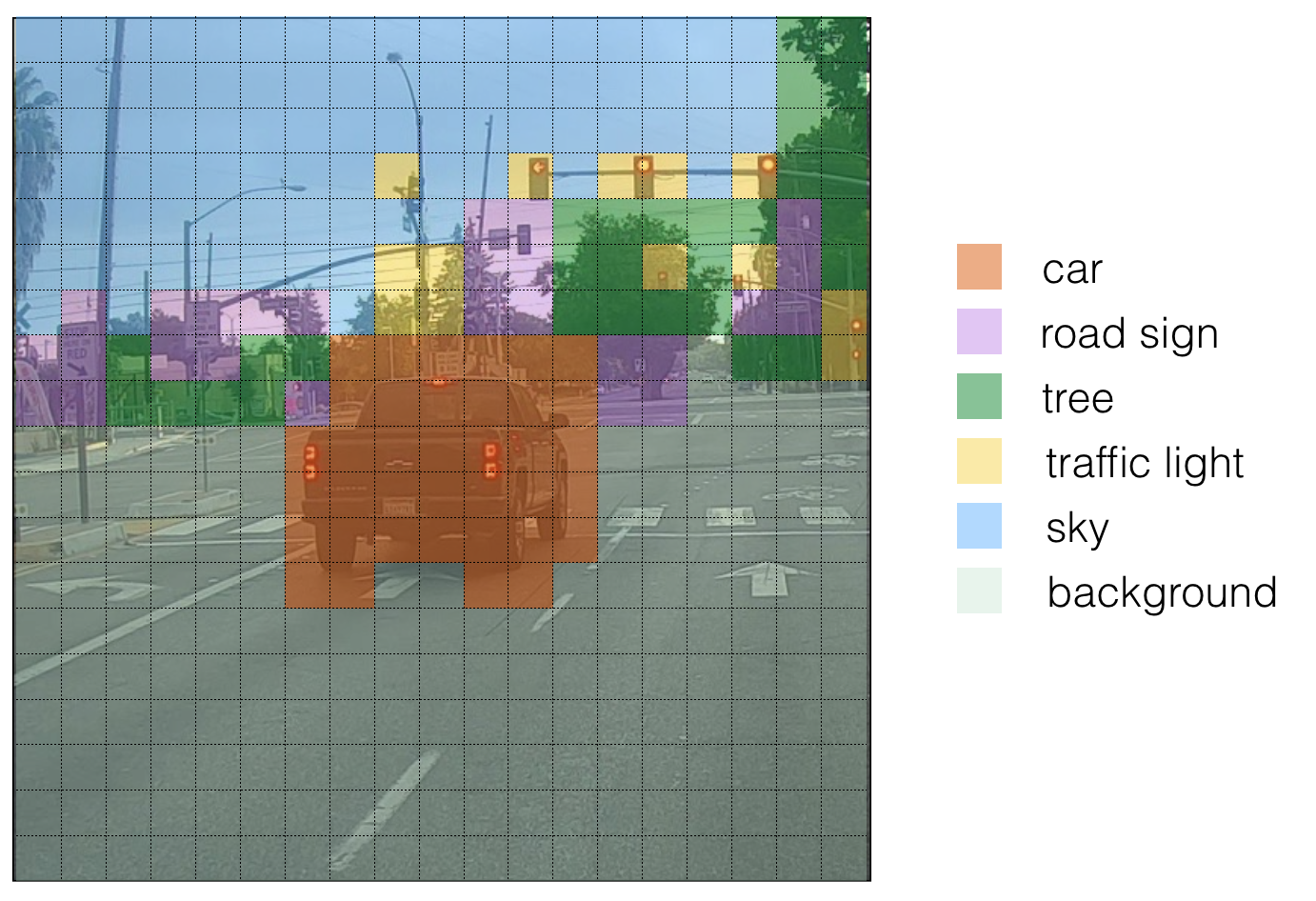


The results of an object detection model (like YOLO - You Only Look Once), which uses deep convolutional neural networks (CNNs) to identify and locate objects in an image. Here's what the outputs mean:
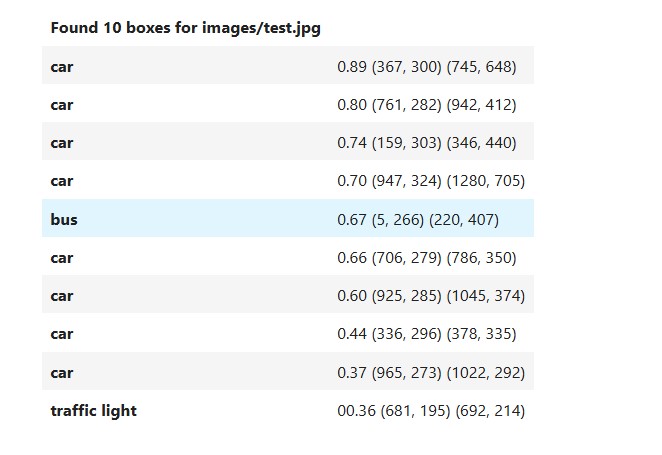
Table of Detections:
Object Classes:
Each row corresponds to a detected object class (e.g., "car", "bus", "traffic light").
Confidence Scores:
The first number in each row is the confidence score, representing the model's certainty that the detected object belongs to the specified class. For example, the model is 89% confident about detecting a "car" in the first row.
Bounding Box Coordinates:
Each row includes two coordinate pairs:
Image with Detections:
The image shows the detected objects with bounding boxes around them.
Orange Boxes:
Each box represents a detected object, with the class label (e.g., "car") and confidence score (e.g., 0.89) displayed above the box.
Bounding Box Overlap:
Multiple bounding boxes may overlap if there are similar objects close to each other (e.g., several cars).
Accuracy: It achieves high precision and recall by predicting bounding boxes and class probabilities simultaneously.
Unified Architecture: Combines detection, classification, and localization in one network, simplifying the pipeline.
Flexibility: Capable of detecting multiple object classes in complex scenes with varying object sizes and orientations.
Grid-Based Localization: Divides the image into a grid, allowing it to detect objects at different locations simultaneously.
End-to-End Training: Fully trainable as a single network, optimizing detection and classification tasks jointly.
Generalization: Performs well across various domains, from autonomous driving to surveillance, due to robust feature extraction.
Non-Max Suppression (NMS): Efficiently removes overlapping bounding boxes, keeping only the most confident detections.
The YOLO architecture encodes object detection outputs into a compact tensor format by flattening the grid-cell dimensions, enabling efficient processing of bounding box and class probabilities for multiple anchors. The Intersection over Union (IoU) metric is integral to evaluating detection performance, quantifying the overlap between predicted and ground-truth bounding boxes. Together, these concepts ensure high-speed, accurate object detection and enable non-max suppression to filter overlapping predictions effectively.
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi - You Only Look Once: Unified, Real-Time Object Detection (2015) (https://arxiv.org/abs/1506.02640)
Joseph Redmon, Ali Farhadi - YOLO9000: Better, Faster, Stronger (2016) (https://arxiv.org/abs/1612.08242)
Allan Zelener - YAD2K: Yet Another Darknet 2 Keras ()