
Introduction
Knowledge retention is a challenge for organizations across various sectors. The loss of intellectual capital when employees leave without an effective knowledge transfer leads to inefficient operations and disrupts business continuity.
The traditional model of knowledge management has created data silos within the organizations and leads to:
- Lack of collaboration between multi-disciplinary teams
- Inadequate mentoring for less experienced employees
- Non-productive time searching for information
- High employee training costs
- Data integration challenges for wholistic insights
A Retrieval Augmented Generation (RAG) based application has been developed in collaboration with a Computer Aided Engineering (CAE) services company to utilize data from that domain. This publication gives an overview of the approach, testing methodology, results and insights based on extensive testing and integration of the RAG components. The application has been validated by domain experts and is able to give domain specific contextual and relevant responses with good accuracy.
Methodology
The knowledge base encompasses CAE domain specific proprietary documents, technical manuals, online lecture transcripts, official websites, expert interviews, channel conversations and Frequently Asked Questions (FAQs). The data is stored in a vector database, where it is indexed and made searchable for real-time retrieval during query operations. The system relies on a three-step process:
- Query Creation: User initiates a query using the Large Language Model.
- Data Retrieval: The system retrieves relevant documents from the vector database using semantic similarity search powered by embeddings.
- Response Generation: The retrieved data is combined with the original user query to generate a contextual and relevant response.
Infrastructure Requirements:
The following hardware specifications were utilized for the development:
- OS – Windows Server 2022 - 64-bit
Ubuntu 22.04.5 LTS (GNU/Linux 5.15.153.1-microsoft-standard-WSL2 x86_64) - Processor – Intel(R) @ Xeon(R) Silver 4114 CPU @ 2.20 GHz 2.19 GHz (2 processors)
- RAM – 128 GB
- Disk Capacity – 1 TB
- GPU - RTX A4000 – 16 GB
Additional development cost includes the API key pricing for OpenAI and Claude.
RAG Components
Vector Database
The vector database serves as the core component for managing unstructured data, transforming domain-specific documents into vector embeddings. This enables advanced semantic similarity search, ensuring relevant documents are retrieved efficiently. Milvus and Pinecone were tested due to their scalability and efficiency in managing high-dimensional data vectors. Additionally, they integrate seamlessly with existing Machine Learning pipelines, streamlining deployment in production environments.
Embedding Model
Embedding models are central to transforming documents into dense, multi-dimensional vector representations. These embeddings capture the semantic meaning of the documents, allowing the system to perform effective searches based on user queries. Embedding models like BERT and GTE are used to map text data into a searchable vector space. Snowflake and GTE embedding models were tested extensively and GTE was chosen for pipeline development.
Large Language Model (LLM)
The LLMs such as GPT, Mistral, or Vicuna, are used to generate responses. The model processes both the query and the retrieved documents, integrating domain-specific knowledge with the user’s query to generate a reasonably accurate response. The combination of these components allows for a dynamic system where real-time information retrieval is integrated with pre-trained knowledge.
Pipelines Evaluated:
The following pipelines were evaluated to arrive at the right combination for CAE specific information:
- Langchain - Milvus – Mistral 7B
- Langchain - Milvus – OpenAI GPT 3.5 Turbo
- Langchain - Milvus – OpenAI GPT 4o
- Langchain - Milvus – OpenAI GPT 4o mini
- Langchain - Milvus – Claude 3.5 Sonnet
- Langchain - Milvus – LlaMA 3.1 - 8B
- Langchain - Milvus – LlaMA 3.1 - 70B
- Langchain - Milvus – LlaVA 7B (Mistral)
- Langchain - Milvus – LlaVA 7B (Vicuna)
- Langchain – Milvus – LlaVA 13B (Vicuna)
- Langchain – Milvus – LlaVA 34B
- Langchain – Milvus – LlaVA-Llama 3
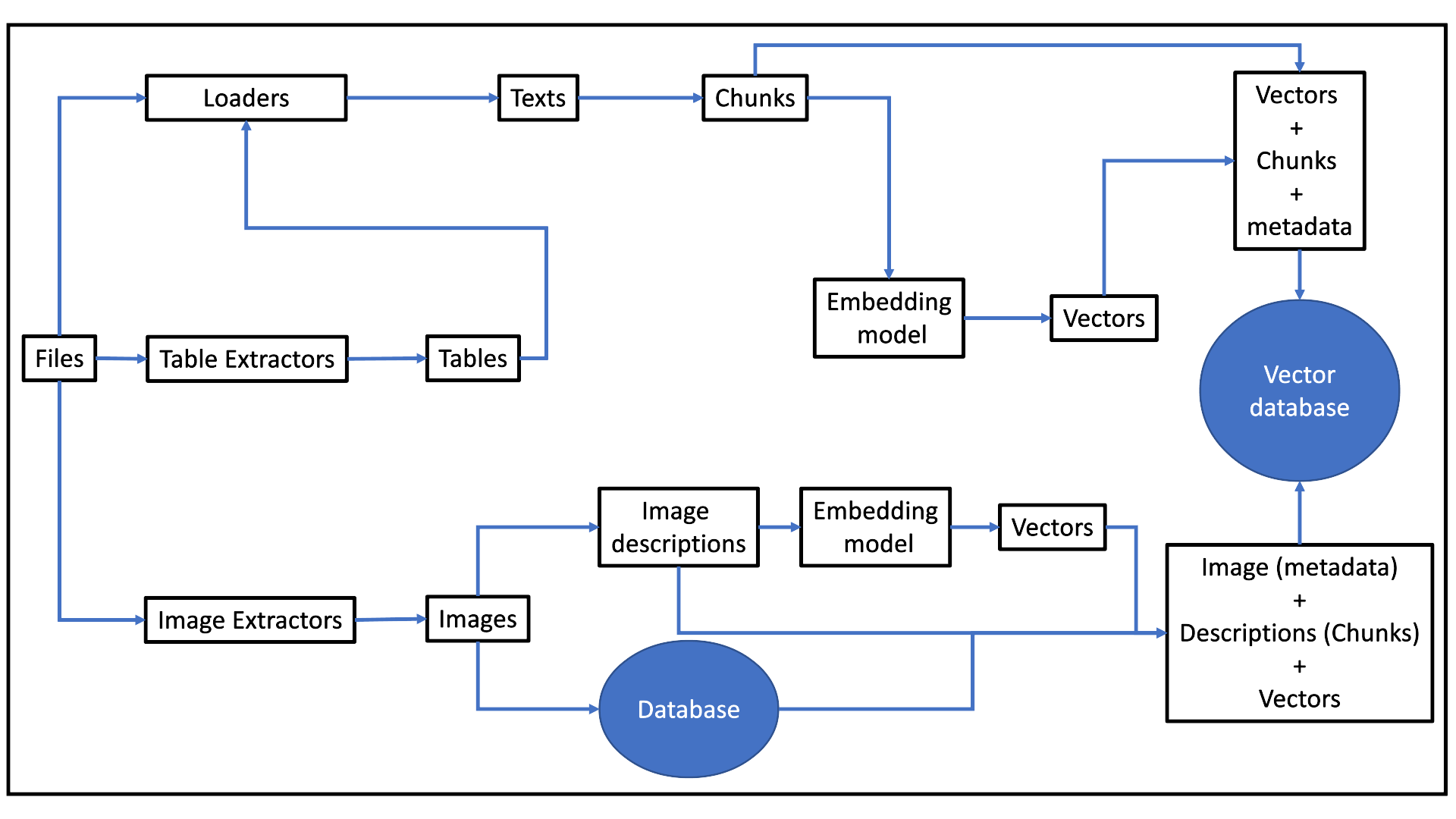
Data Loading System
The data loading system handles the ingestion and processing of documents into the vector database. It involves a step-by-step process that transforms raw data into searchable vectors:
Text and Table processing
- Documents are parsed, and text is chunked for embedding. Chunking is a pre-processing technique that involves dividing texts into smaller segments known as "chunks." Each chunk is processed through the embedding model to generate vector representations.
- Vector representations: The mathematical encoding, including words, sentences, photos, or any other sort of data, into numerical vectors in a multi-dimensional space is known as a vector representation.
A sentence can be transformed into a vector using an embedding model. The code along with its output that demonstrates this conversion into a vector is shown below.
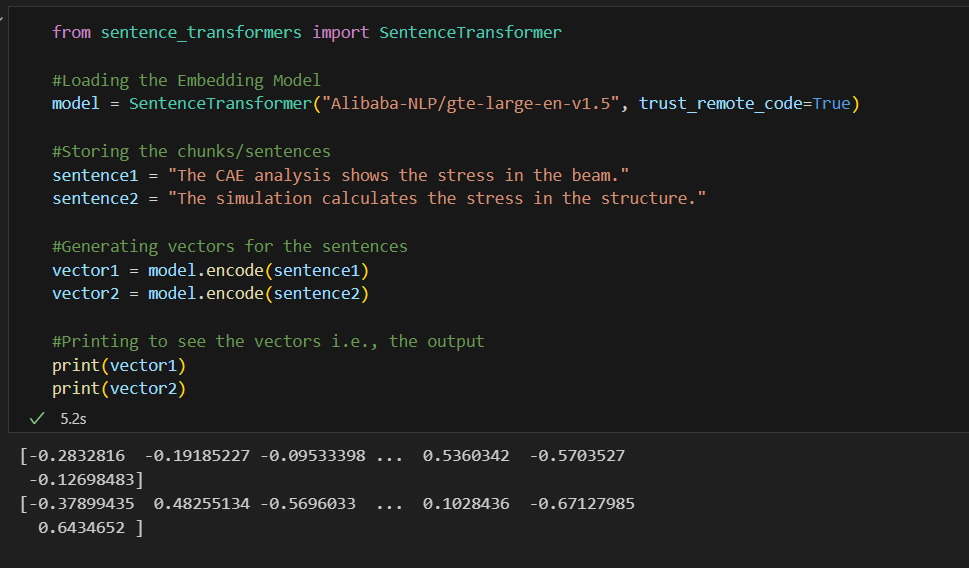
The vector representations of each chunk will be stored along with metadata in the vector database.
Image processing
Images are extracted and sent to vision LLMs for generating descriptions. These descriptions are converted into vectors and stored in the database alongside the images. This structured approach ensures that all relevant data is searchable, allowing the AI assistant to retrieve and process information from diverse sources.
The workflow is shown in the figure below.
Retrieving System and Generation System
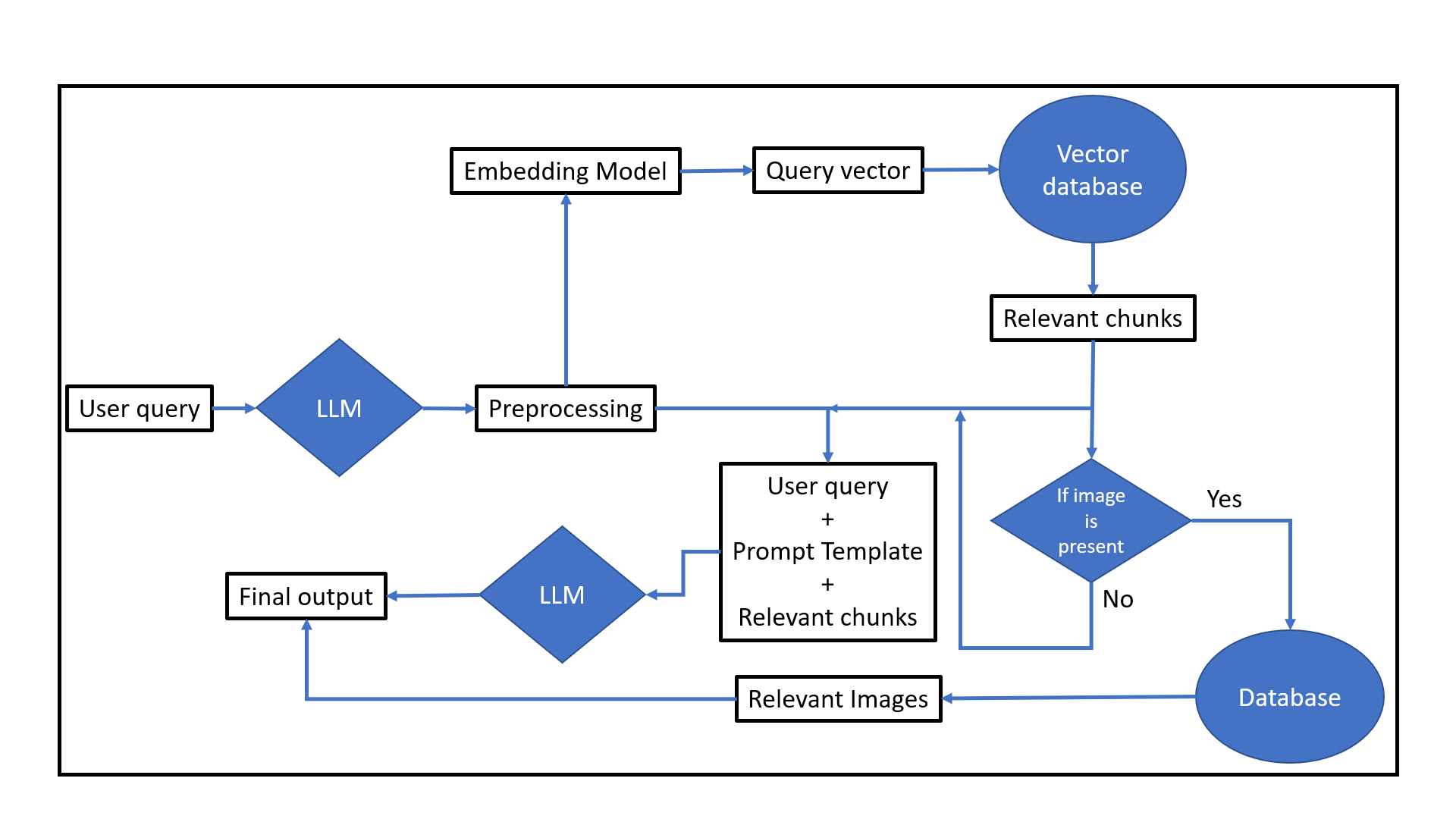
The LLM is used initially to process user queries, rephrasing them for best retrieval. An embedding model is used to convert the rephrased question into a vector representation, which makes it easier to find relevant text chunks in the Milvus vector database. The question can now be represented in a high-dimensional space, where each dimension represents distinct semantic aspects of the text.
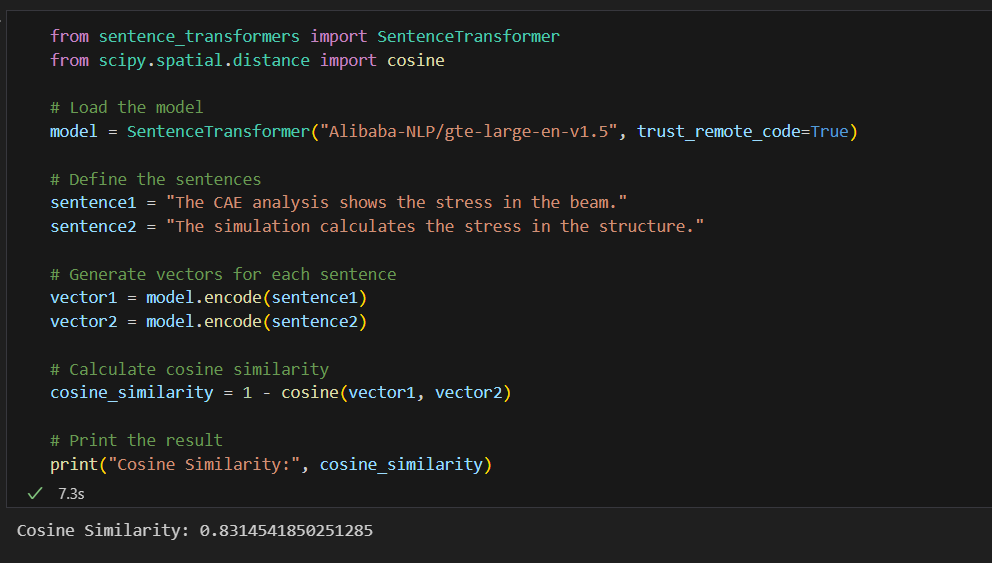
Cosine similarity is used as the main comparison metric to find relevant chunks. An effective way to assess the degree of similarity between the vectors of text chunks and the vector representations of the question is to use cosine similarity, which calculates the cosine of the angle between the two. The associated text chunk and the query have a closer association when the cosine similarity score is higher, indicating that the chunk is probably relevant to the query. The cosine similarity between two closely related sentences is displayed below.
At the same time the system looks for any image IDs added in the meta data that would necessitate fetching related images from MongoDB. To generate a comprehensive final response, the system combines the rephrased query with a prompt template that guides the LLM to formulate an answer using the retrieved content, including both text chunks and relevant images.
The workflow is shown in the figure below.
Pipeline Evaluation
The system was evaluated through a series of structured experiments. The primary goal was to determine the best combination of vector databases, embedding models, and large language models (LLMs) for providing contextual, accurate and relevant responses. The experiments focused on tuning the following parameters to optimize the pipeline:
Top K Value:
The Top K parameter controls the number of most relevant documents retrieved from the vector database for any given query. We experimented with different Top K values (e.g., 5, 10, 50) to balance retrieval relevance and computational efficiency.
Similarity Threshold:
The similarity threshold determines how closely the retrieved documents match the query in semantic space. This was evaluated by adjusting cosine similarity thresholds (e.g., 30%, 60%) to find the optimal balance between retrieval accuracy and the quality of the generated response.
Index Type:
Different vector database index types were tested (IVF-FLAT, HNSW) to compare retrieval speeds and accuracy. IVF-FLAT provided a good trade-off between speed and similarity score, while HNSW (Hierarchical Navigable Small World) offered higher accuracy at the cost of speed.
Other iterations tested are listed below:
- Iteration 1: Evaluated retrieval accuracy between Mistral and GPT 3.5 Turbo using different index types.
- Iteration 2: Compared performance of GPT 4o vs Claude 3.5 Sonnet for index optimization.
- Iteration 3: Assessed the performance of LLaMA 3.1 across various retrieval and generation tasks.
- Iteration 4: Tested the default LangChain framework to establish a baseline for pipeline efficiency.
- Iteration 5: Conducted an initial evaluation of Pinecone as an alternative vector database solution.
- Iteration 6: Performed text-based evaluations on Vision models to assess their understanding of image-related tasks.
- Iteration 7: Tested the performance of new loaders for improving data ingestion efficiency.
- Iteration 8: Re-evaluated Pinecone performance specifically on a Windows Server environment.
- Iteration 9: Tuned the similarity threshold to optimize retrieval relevance and response accuracy.
- Iteration 10: Evaluated different chunk sizes and overlaps to enhance retrieval accuracy without increasing latency.
- Iteration 11: Conducted Vision description tests to assess the generation quality of domain-specific image descriptions.
- Iteration 12: Performed a general mathematics evaluation to assess the numerical reasoning capability of the LLMs.
- Iteration 13: Focused on domain-specific mathematical queries to test specialized mathematical problem-solving.
- Iteration 14: Evaluated Vision prompts to test model responses based on image analysis queries.
- Iteration 15: Assessed the accuracy of model responses in table-related queries.
- Iteration 16: Conducted a Top K evaluation to determine the optimal K value for licensed models.
- Iteration 17: Tested GPT 4o mini across tasks involving tables, mathematics, and text generation.
- Iteration 18: Evaluated GPT 4o mini for vision-based tasks to assess its capability in image-related queries.
- Iteration 19: Performed a comprehensive multimodal evaluation to test the pipeline's performance across text, tables, and images.
Evaluation Metrics
To evaluate the effectiveness of the various configurations, we used the following metrics:
Response Accuracy:
The accuracy of responses generated by the LLMs was measured based on how well they addressed the user's query, incorporating the correct information retrieved from the vector database.
Relevance Score:
Each retrieved document’s relevance to the query was rated on a scale from 0 to 5, with 5 representing a perfect match and 0 indicating irrelevance. These relevance scores were aggregated to assess overall retrieval performance.
Latency:
The response time from query to answer was measured to ensure the system could provide real-time responses. Latency was particularly important when testing different Top K values and indexing methods.
Memory and Computational Efficiency:
The system’s memory usage and computational load were monitored to assess the trade-offs between higher retrieval accuracy and processing efficiency, particularly when using more complex models such as LLaMA 70B.
RAGAS Metrics
In addition, RAGAS metrics were incorporated to provide deeper insights into the quality of the responses:
Contextual Precision:
Measures how accurately the information retrieved from the vector database matches the query’s intent. High contextual precision indicates that the retrieved information is directly relevant to the user's question.
Contextual Recall:
Evaluates how comprehensively the retrieved information addresses all aspects of the query. High contextual recall indicates that the system is not only retrieving relevant chunks but is also covering the full scope of the query.
Answer Relevancy:
Focuses on the relevance of the final generated answer in relation to both the query and the retrieved documents. This metric assesses how well the LLM integrates the retrieved information to form a coherent and contextually appropriate response.
Faithfulness:
Measures the factual consistency between the retrieved documents and the generated answer. High faithfulness ensures that the LLM does not introduce hallucinations or incorrect information in the final response, particularly critical in domain-specific applications like CAE.
Experiment Results
Giskard Evaluation
Giskard RAG (Retriever-Augmented Generation) evaluation is a framework designed to evaluate the performance of RAG pipelines, especially in the context of NLP systems like question-answers or summarization tasks. The idea behind RAG is to combine the strengths of two components: a retriever, which fetches relevant information from a knowledge base, and a generator, which formulates natural language responses based on the retrieved information.
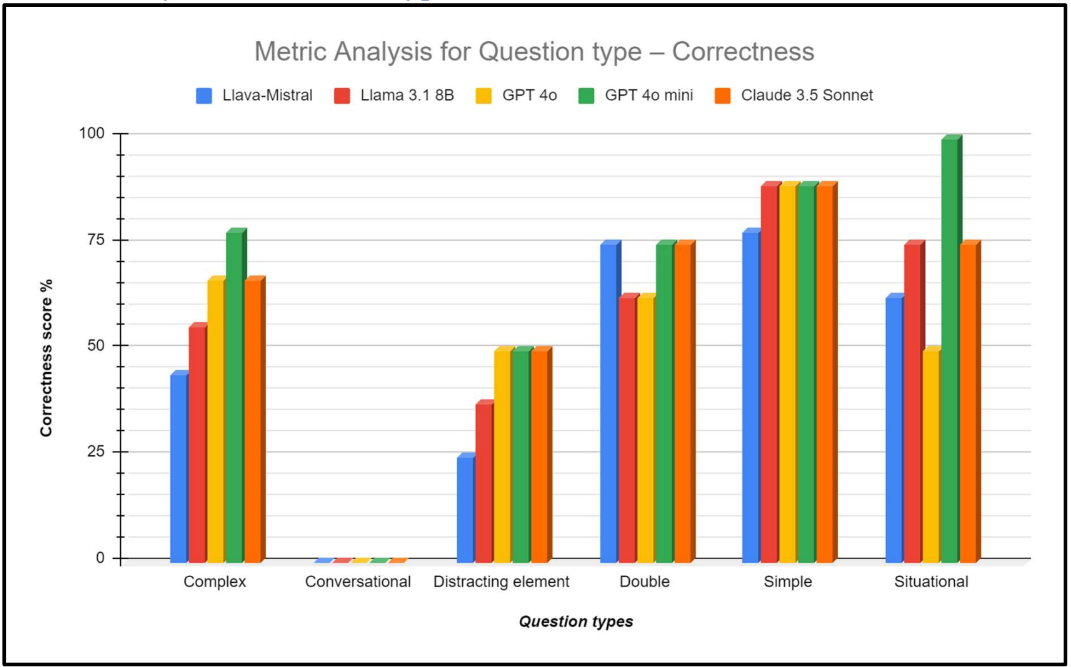
Metric Analysis for Question type – Correctness
- Simple questions: Simple questions generated from an excerpt of the knowledge base
- Complex questions: Questions made more complex by paraphrasing
- Distracting questions: Questions made to confuse the retrieval part of the RAG with a distracting element from the knowledge base but irrelevant to the question
- Situational questions: Questions including user context to evaluate the ability of the generation to produce relevant answer according to the context
- Double questions: Questions with two distinct parts to evaluate the capabilities of the query rewriter of the RAG
- Conversational questions: Questions made as part of a conversation, first message describes the context of the question that is asked in the last message, also tests the rewriter
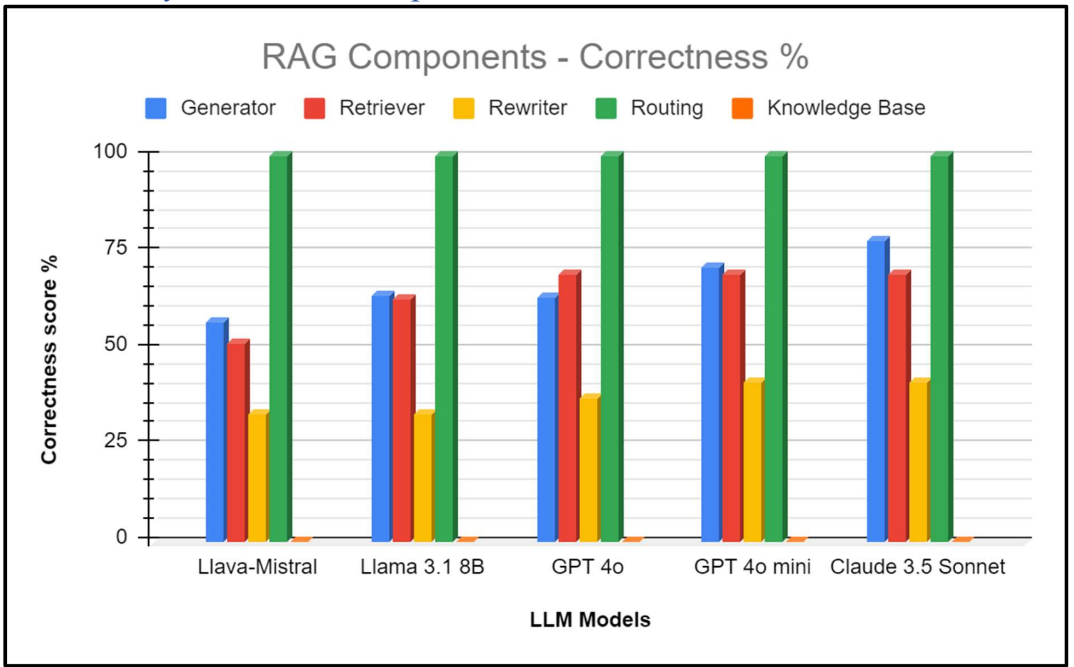
Metric Analysis for RAG Components – Correctness
Target RAG components
-
Generator
- The LLM used inside the RAG to generate the answers
-
Retriever
- Fetch relevant documents from the knowledge base according to a user query
-
Rewriter
- Rewrite the user query to make it more relevant to the knowledge base or to account for chat history
-
Router
- Filter the query of the user based on his intentions (intentions detection)
-
Knowledge Base
- The set of documents given to the RAG to generate the answers
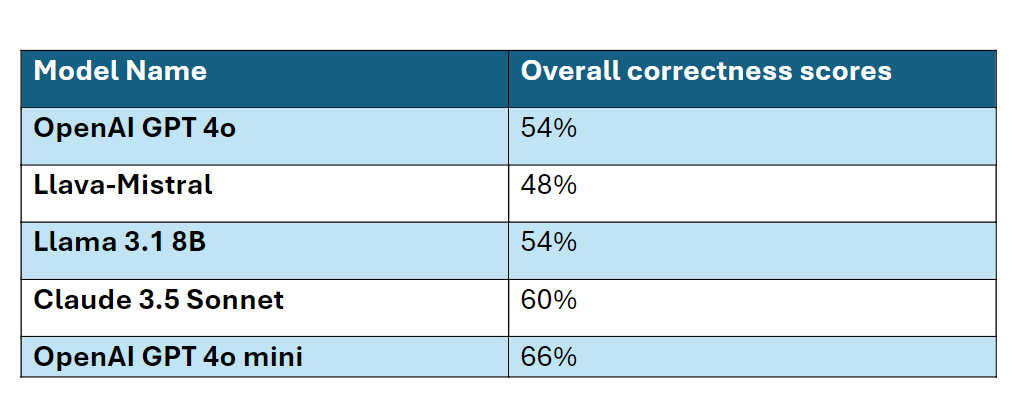
Based on the text-based Giskard evaluation metrics, for closed-source models, OpenAI 4o mini outperforms Claude 3.5 Sonnet and GPT 4o, and for open-source models, Llama 3.1 8B outperforms Llava -Mistral. The results are shown below.
DeepEval Evaluation
A dataset of 20 questions was generated from the files and unit test was conducted in the pipelines. Bias is one of the metrics which was introduced during the pytest. Along with the existing RAGAS metrics —contextual precision, contextual recall, answer relevancy, and faithfulness, Bias has now been incorporated as an additional evaluation criterion for the unit tests. A threshold of 0.5 was set for all metrics, meaning any test case scoring below 0.5 on even a single metric would result in a failed evaluation.
Note: The bias metric determines whether your LLM output contains gender, racial, or political bias. Therefore, Bias should fall below 0.5 with 0% to pass the test.
Unit Test – LLaMA3.1 – 20 Test Cases

It is observed that the LLaMA3.1 has passed 13 out of 20 test cases in the unit testing.
Considering that a test case is deemed successful only if all metrics exceed the 50% threshold, the following metrics analysis table was created to provide a better understanding of the unit testing results.
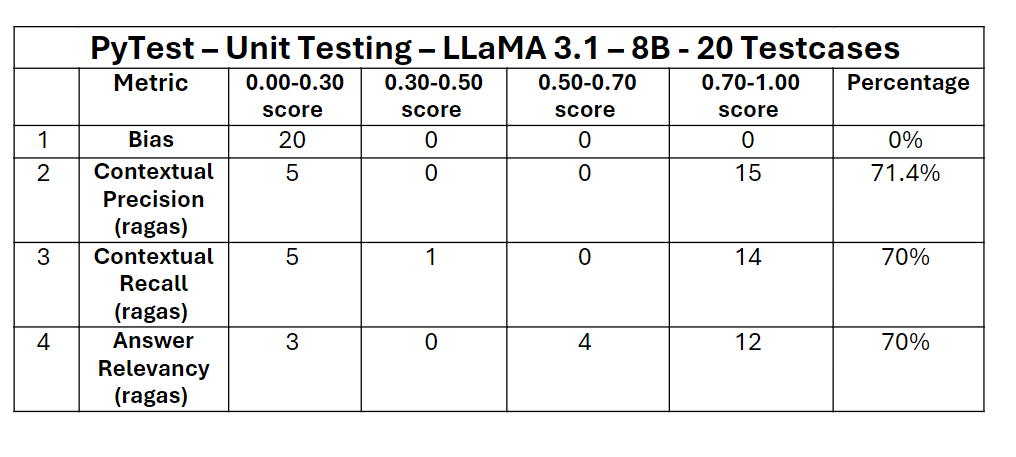
The table above presents the unit testing results, with metric definitions provided in the previous section. This table summarizes the outcomes for 20-unit tests conducted on the pipeline. In each test case, the bias metric consistently scored 0, leading to a count of 20 in the 0.00 to 0.30 range. For bias, a score of 0% is considered a pass, as it indicates no presence of gender, racial, or political bias in the output, which is ideal. This result shows the LLM's responses are neutral and free from potentially problematic or offensive content. All three remaining metrics scored above 70%, and the overall unit test achieved a score of 65%, passing 13 out of 20 test cases. For a test case to pass, each metric must individually score above 50%.
Unit test - GPT – 4o - 20 Test Cases:

The GPT-4o has identical results to LLaMA3.1 in the unit testing where it has passed in 13 out 20 tests.
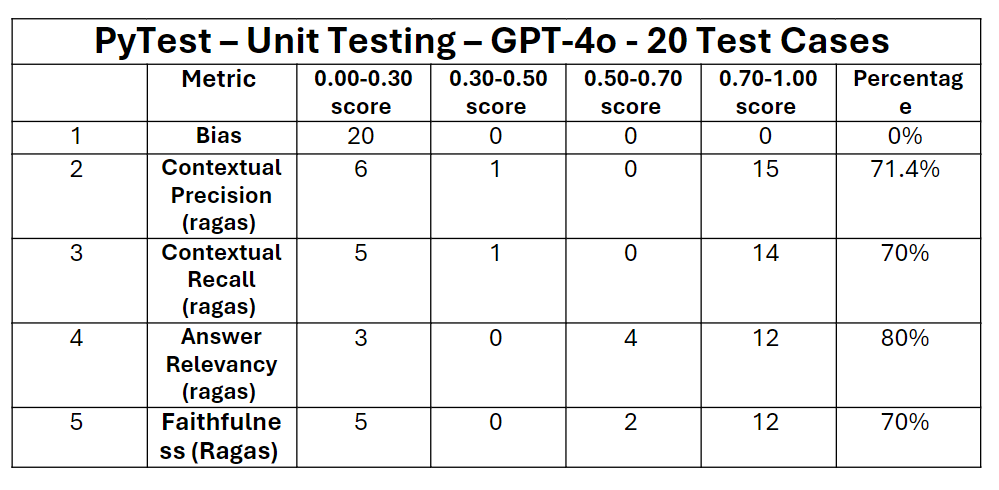
The table above presents the unit testing results, with metric definitions provided in the previous section. This table summarizes the outcomes for 20-unit tests conducted on the pipeline. In each test case, the bias metric consistently scored 0, leading to a count of 20 in the 0.00 to 0.30 range. For bias, a score of 0% is considered a pass, as it indicates no presence of gender, racial, or political bias in the output, which is ideal. This result shows the LLM's responses are neutral and free from potentially problematic or offensive content. All four remaining metrics scored above 70%, and the overall unit test achieved a score of 65%, passing 13 out of 20 test cases. For a test case to pass, each metric must individually score above 50%.
Vector Database Performance
Milvus demonstrated high efficiency in retrieving documents at scale, with IVF-FLAT providing the best balance between retrieval time and accuracy. HNSW offered slightly better accuracy but introduced significant latency at larger scales, making it less practical for real-time applications.
LLM Performance:
- GPT-4o: Excelled in handling complex, multi-step queries and provided the most accurate responses, particularly when paired with larger Top K values.
- Claude 3.5 Sonnet: Performed well with simpler queries and required fewer computational resources but was not concise and precise with answers regarding CAE domain specific content.
- LLaMA 3.1 8B: Outperformed other open-source models in terms of response relevance but required more tuning in similarity threshold selection.
- GPT 4o mini: The giskard examination showed that GPT 4o mini outperformed than 4o, but another important finding is that the vision description irrelevancy is more than 4o.
- Vision Models (LLaVA- Mistral & LLaVA - 34B): Both models performed well on image-based queries, with LLaVA 34B showing slightly better accuracy in domain-specific image description tasks.
Discussion
In the initial development phase, due diligence was done to test numerous open-source and licensed large language models (LLMs). The availability of more advanced LLMs in a short timeframe enabled us to test increasingly powerful options. Initial iterations included models like Falcon, LLaMA-2, and Mistral 7B. The primary motivation for adopting a Retrieval Augmented Generation (RAG) approach was the rapid advancements in Generative AI, promising continual access to faster, more capable models suited to complex tasks.
The knowledge base contains approximately 2,500 files related to the CAE domain, enabling the LLM to deliver content-rich answers to user queries.
Key components were evaluated based on variety of criteria, including retrieval accuracy, response quality and system efficiency. While the detailed results of the final configuration remain proprietary, the exploration phase provided valuable insights. The system demonstrated strong performance in handling a variety of input types including text, images, and mathematical queries. Evaluation metrics such as contextual precision, recall and answer relevancy were used to measure the system’s performance. Across all the iterations, the system consistently met or at times exceeded the predefined threshold (0.5), ensuring a reliable retrieval of relevant documents and quality of response generation.
By incorporating the multimodal capabilities, the pipeline effectively supports diverse use cases within the CAE domain. A user-friendly GUI enables seamless switching between input types, making domain knowledge easily accessible. A few snapshots of the application is shown below.
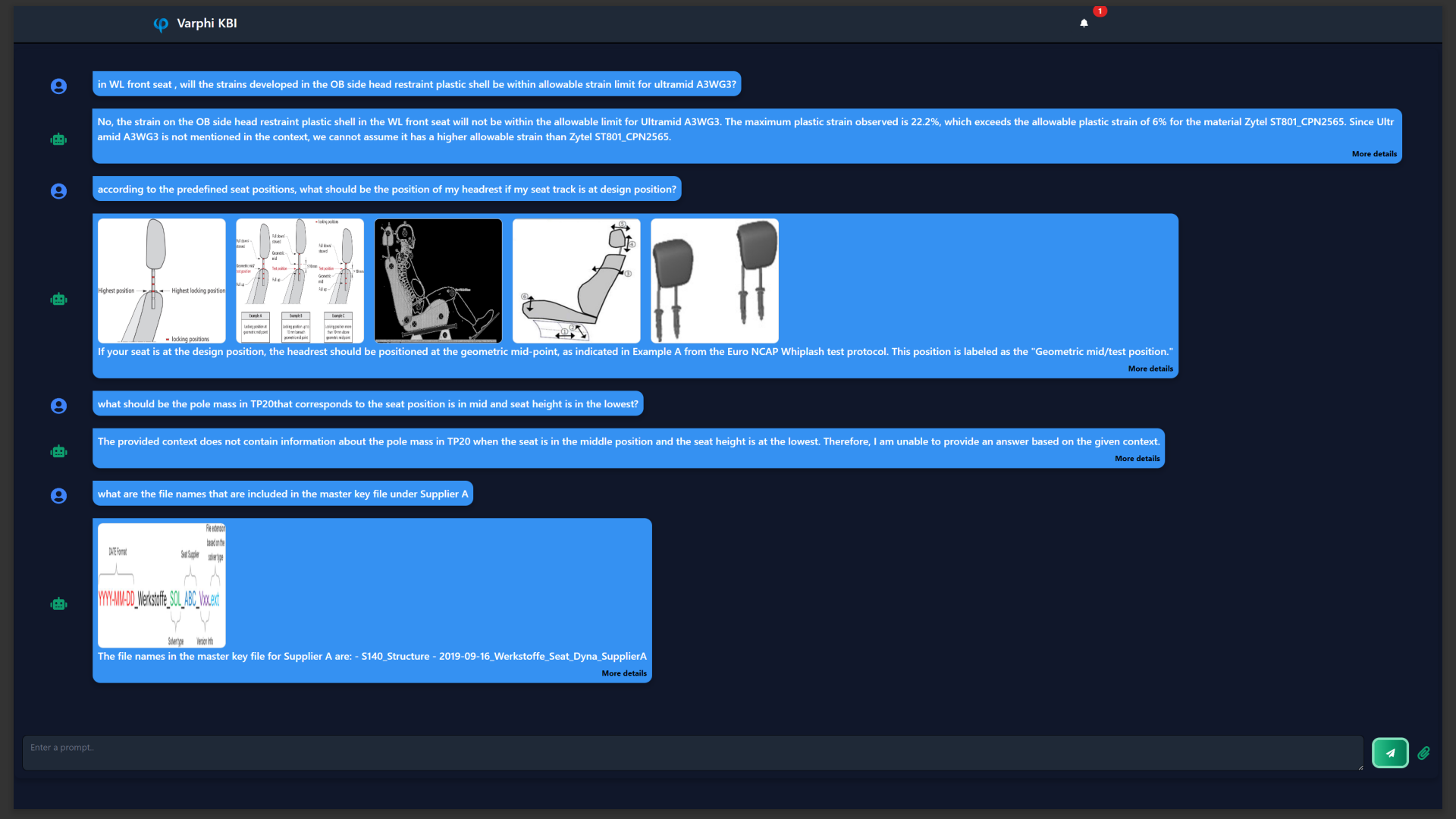
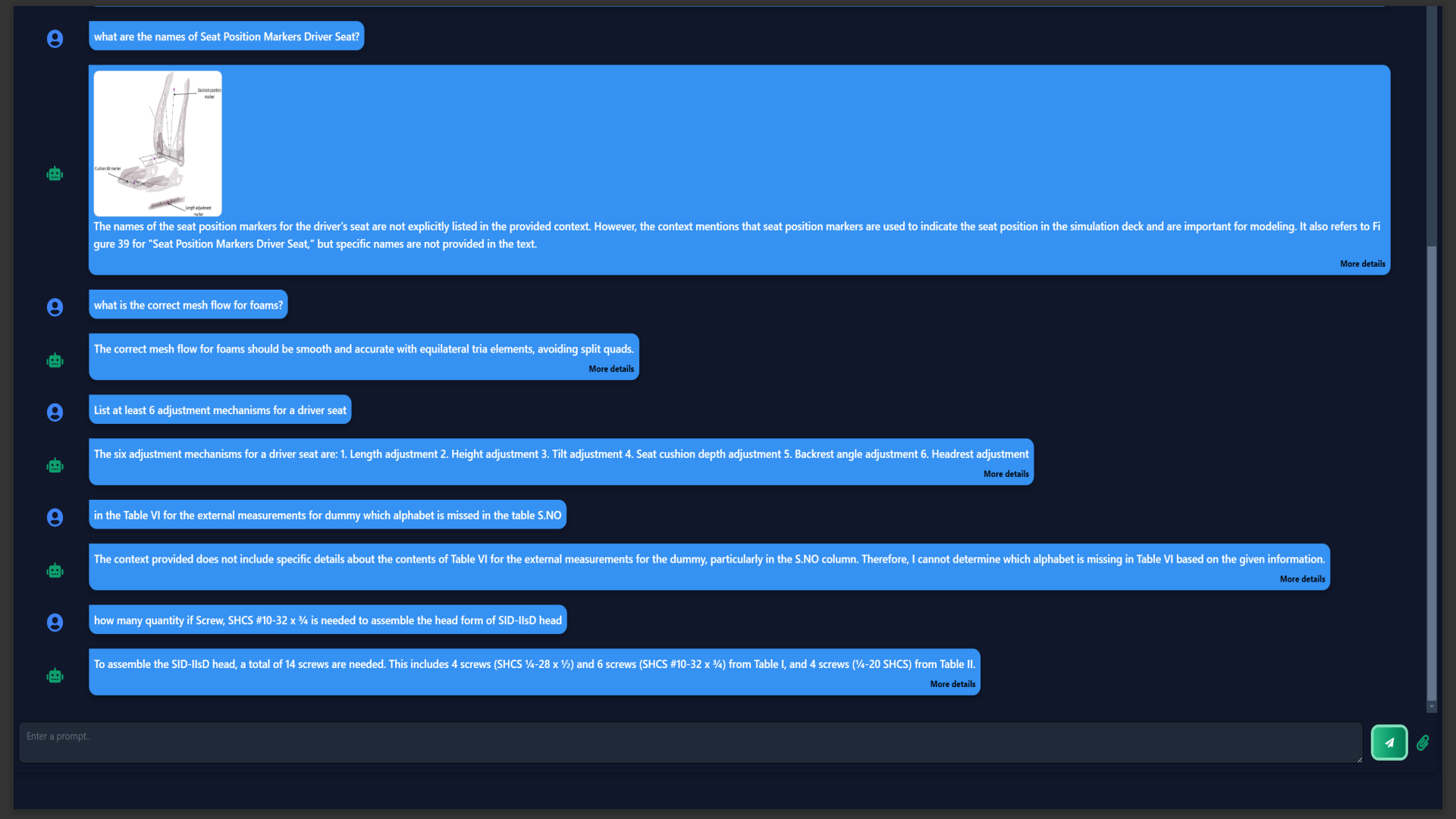
Conclusion
To address the challenge of knowledge retention in organisations, an AI-driven assistant with multimodal data handling capabilities was developed by integrating RAG techniques for CAE domain. The system demonstrates strong performance in handling text, images, and mathematical queries, with GPT-4o-mini, GPT-4o, Claude 3.5 Sonnet, and LLaMA 3.1 8B emerging as top performers.
For the given experimental environment set up, the model performed with good accuracy hence validating the approach for knowledge retention. Currently in progress is the deployment of the model in a real-time environment, where knowledge base is constantly updated, and multiple users will be accessing the application.
The model will be improved to make sure the company never “forgets” critical information and keeps the employees informed, hence maintaining competitive advantage and improved financial metrics.
References:
- https://huggingface.co/
- https://milvus.io/
- https://www.langchain.com/
- https://openai.com/index/
- https://www.anthropic.com/news/claude-3-5-sonnet
- https://python.langchain.com/docs/integrations/llms/ollama/
- https://www.pinecone.io/
- https://github.com/Giskard-AI/giskard
- https://github.com/confident-ai/deepeval