ASKBOT: An Integrated AI based chatbot for Voice, Text, Image Intelligence and analysis
Hub:GDG Babcock
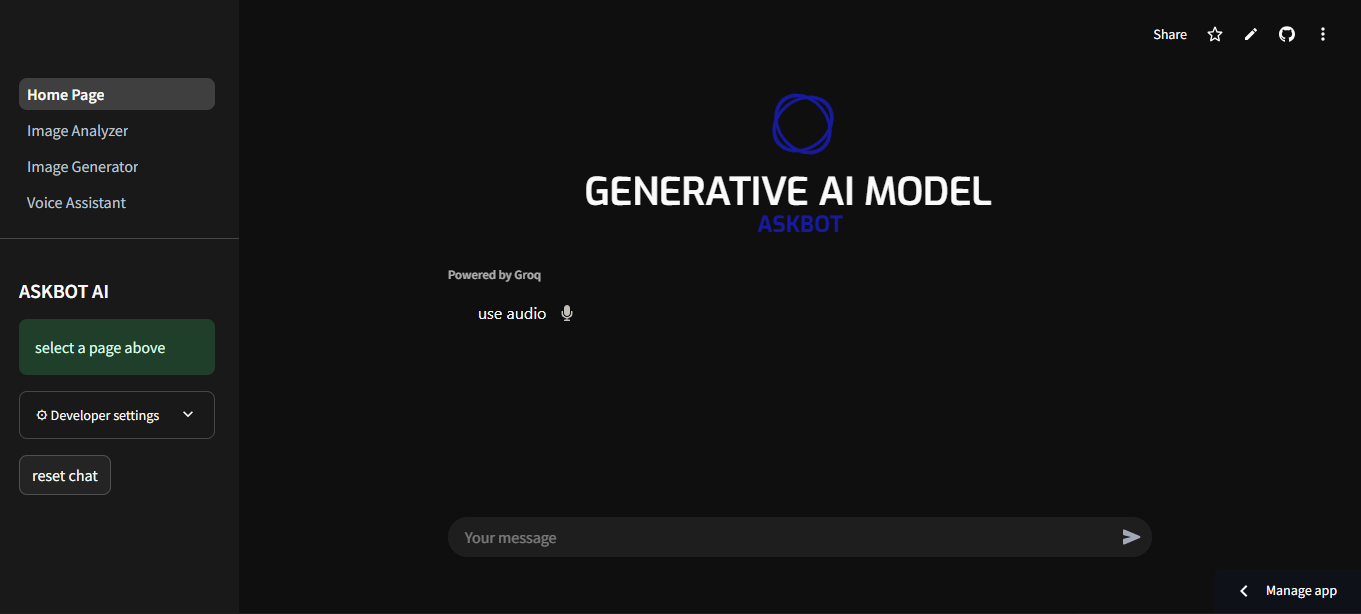
A multi-modal conversational AI platform that integrates advanced language processing capabilities with voice, text, and image analysis functionalities. ASKBOT serves as a sophisticated virtual assistant, enabling seamless communication with users through a range of interfaces, including:

!
.
.
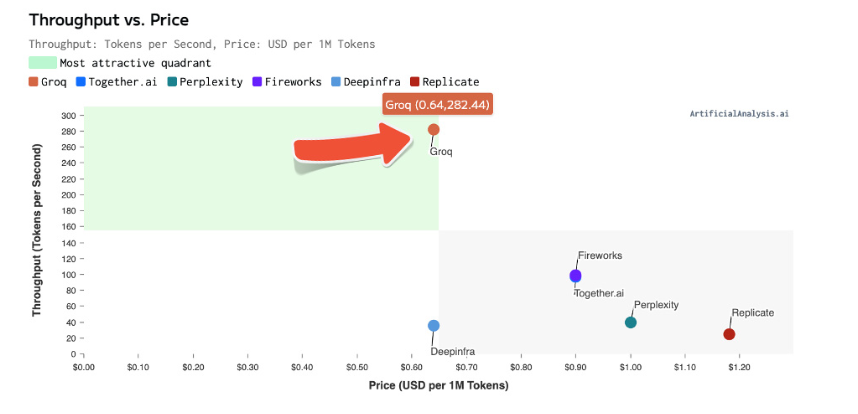
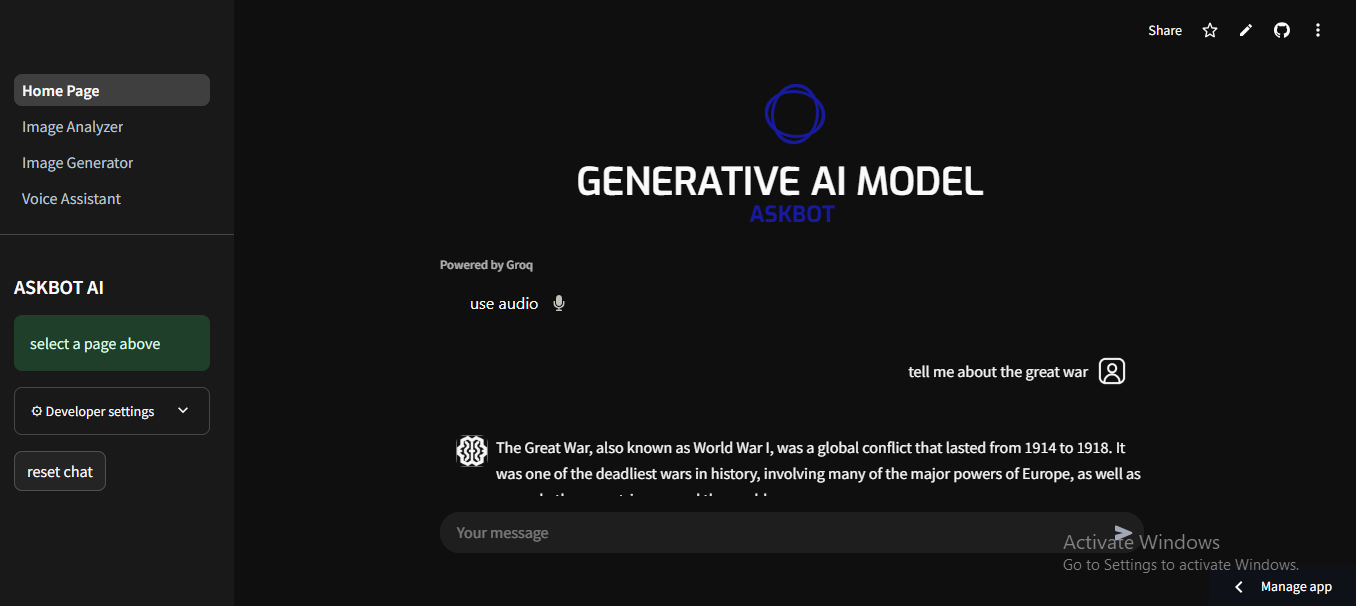
the scope and aim of this project was to develop a fast AI system for any scale or use case by user, and giving the user different mediums of interaction
other requirements:
Front-end Development:
Back-end Development:
API:
Large Language Models:
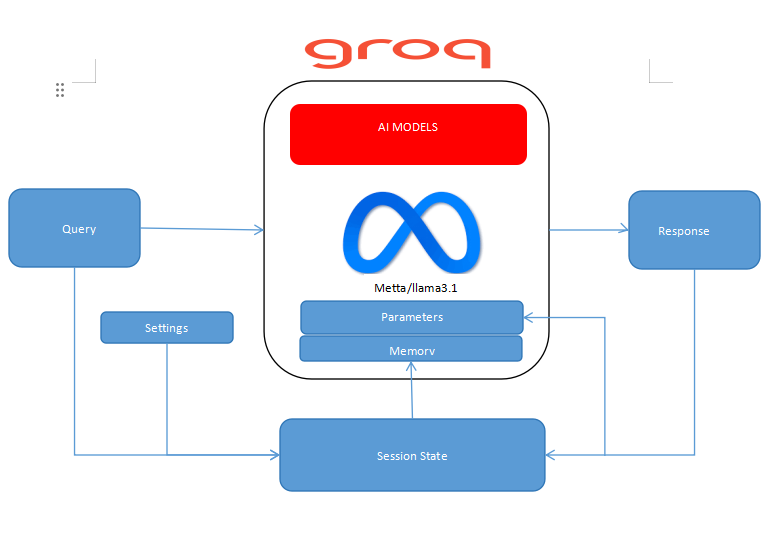
The text based Model consist of the front-end, the API and session state to store the values of previous responses, with a parameter settings on the front-end
You will have to import your need packages, then store the API key to interact with groq models
#store the api key client = Groq( api_key= os.getenv("GROQ_API_key") )
use a session state to send prompts and responses to the memory of the AI
#create a session state to store all prompts into the memory if "messages" not in st.session_state: st.session_state["messages"] = [] )
store the values of parameters as setting, in which the value can be changed on the frontend
# Parameters with st.sidebar.expander("⚙ Developer settings"): temp = st.slider("Temperature", 0.0, 2.0, value=1.0, help="randomness of response") max_tokens = st.slider("Max Tokens", 0, 1024, value=300, help="unit of word for characters for input and output") stream = st.toggle("Stream", value=True, help="ability to deliver generated content") top_p = st.slider("Top P", 0.0, 1.0, help="It's not recommended to alter both the temperature and the top-p, cummulative probability.") stop_seq = st.text_input("Stop Sequence", help="word to stop generation)
# For each message of either role "user" or "assistant" add to message in session state for message in st.session_state.messages: # {"role": "user", "content": "hello world"} avatar = "./assets/images/user_avatar.png" if message["role"]=="user" else "./assets/images/ai_avatarcom.png" if message["role"] == "assistant" else "👋" with st.chat_message(message["role"], avatar = avatar): st.markdown(message["content"])
Finally deliver the response only when a prompt is given and append prompt to user and response to assistant
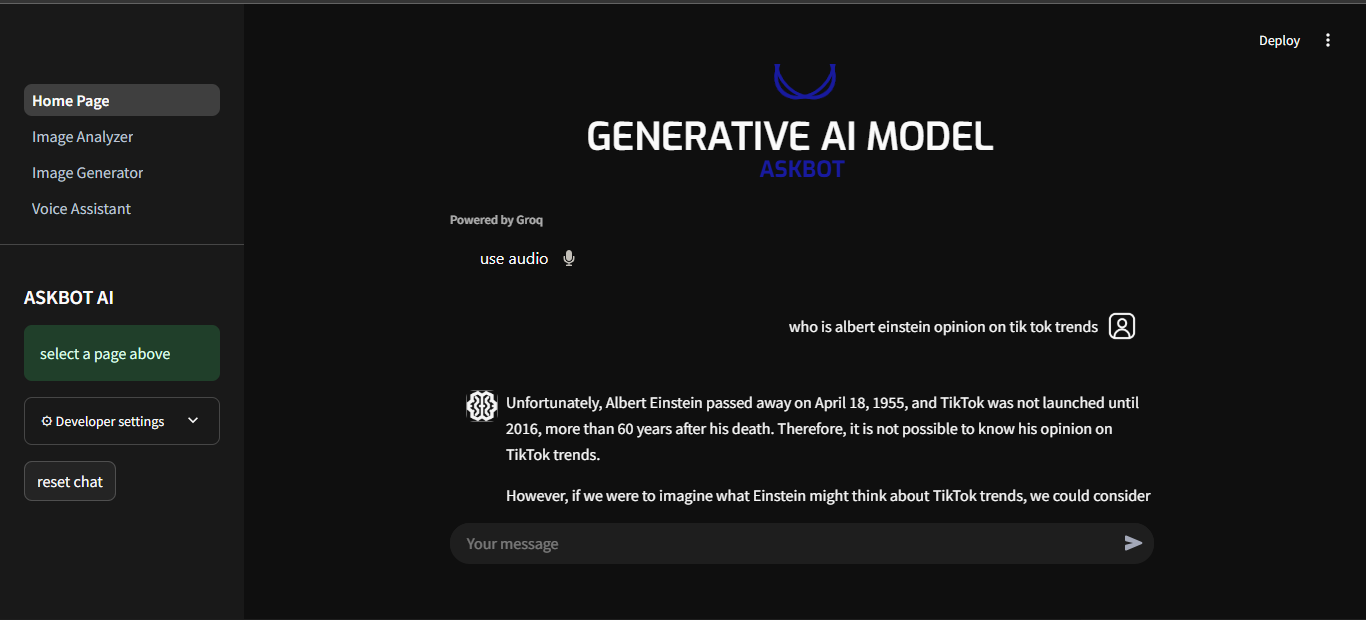
if prompt := st.chat_input(key="input",disabled=not input): # add the message/prompt to the messages list # show the new user message recorded_audio = None with st.chat_message("user", avatar = "./assets/images/user_avatar.png"): st.write(prompt) st.session_state.messages.append( {"role": "user", "content": prompt} ) # Make API call and show the model response with st.chat_message("assistant", avatar= "./assets/images/ai_avatarcom.png"): # create empty container for response response_text = st.empty() # Make the API call to Groq completion = client.chat.completions.create( model= "llama-3.1-8b-instant", messages=st.session_state.messages, stream=stream, temperature=temp, max_tokens=max_tokens, stop=stop_seq, top_p=top_p ) # Display the full message full_response = "" if stream: for chunk in completion: full_response += chunk.choices[0].delta.content or "" response_text.write(full_response) else: with st.spinner("Generating"): completion.choices[0].message.content # Add assistant message to the messages list st.session_state.messages.append({"role": "assistant", "content": full_response})
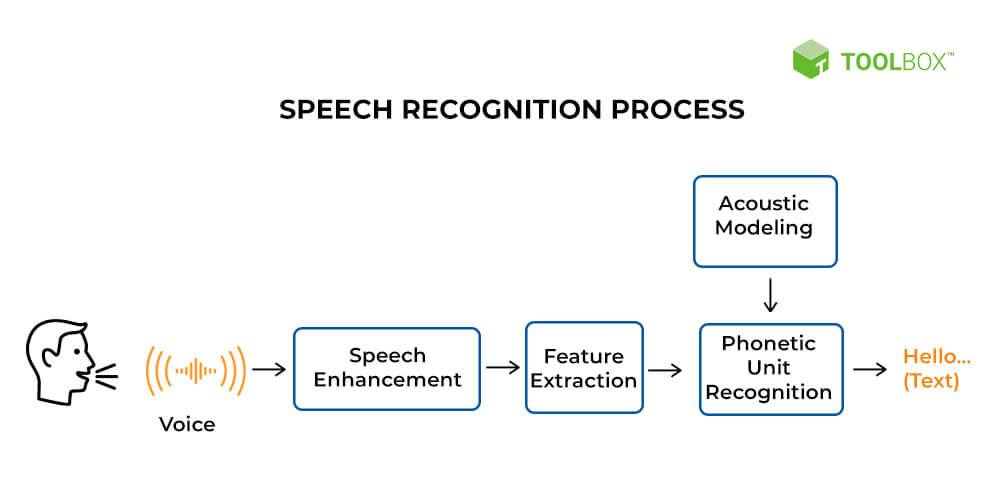
model phases:
Transcribing the audio using whisper:
#transcribe the audio to text the process it with the LLM def transcribe_audio(client, audio_path): #transcription history if "voicebxt" not in st.session_state: st.session_state["voicebxt"] = [] with open(audio_path,"rb") as audio_file: transcript = client.audio.transcriptions.create(model= "whisper-large-v3-Turbo",file=audio_file) print(transcript.text) prompt = transcript.text
sending the response to the llama model
with st.chat_message("user", avatar = "./assets/images/user_avatar.png"): st.write(prompt) st.session_state.voicebxt.append( {"role": "user", "content": prompt} ) st.write("mic response ") # Make API call and show the model response with st.chat_message("assistant", avatar= "./assets/images/ai_avatarcom.png"): # create empty container for response response_text = st.empty() # Make the API call to Groq completion = client.chat.completions.create( model= "llama-3.1-8b-instant", messages =st.session_state.voicebxt, stream=stream, temperature=temp, max_tokens=max_tokens, stop=stop_seq, top_p=top_p ) # Display the full message full_response = "" if stream: for chunk in completion: full_response += chunk.choices[0].delta.content or "" response_text.write(full_response) else: with st.spinner("Generating"): completion.choices[0].messages.content # Add assistant message to the messages list st.session_state.voicebxt.append({"role": "assistant", "content": full_response}) #display the transcription and answer after if recorded_audio: audio_file= "audio.mp3" with open( audio_file, "wb") as f: f.write(recorded_audio) transcribed_text = transcribe_audio(client, audio_file)
model phases:
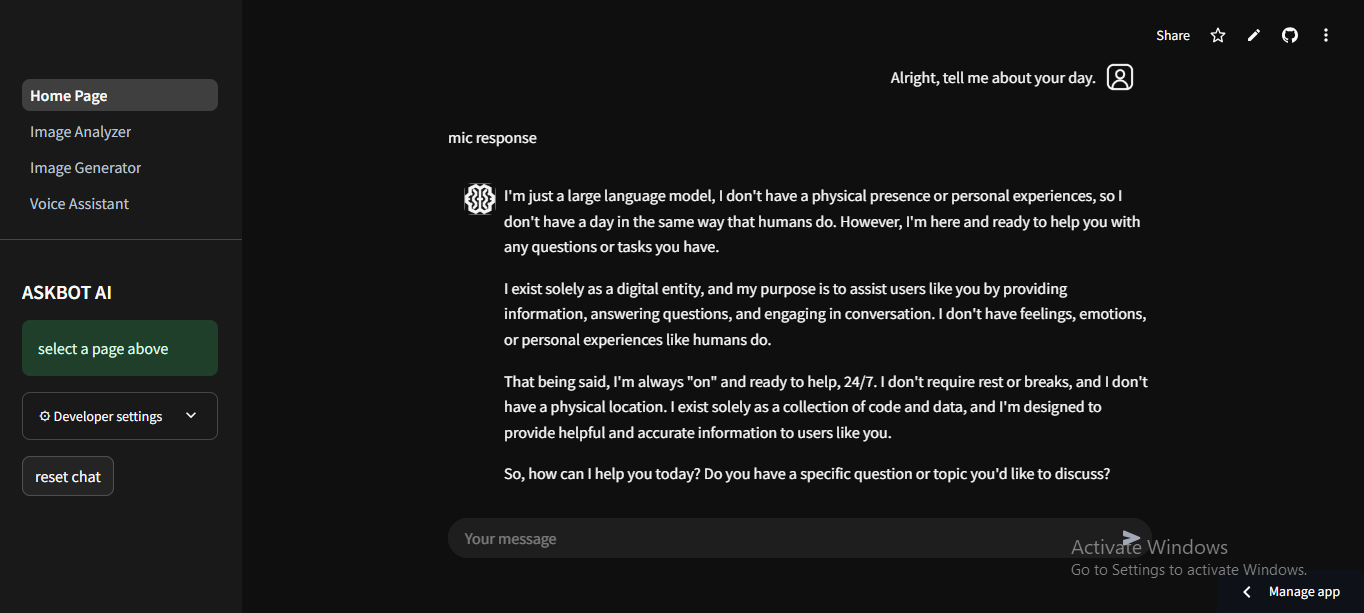
the model also gives users the ability to change voice of the assistant
#store different voices in a session state if "voice" not in st.session_state: st.session_state["voice"] = "" #voice option for changing voices st.session_state.voice = st.sidebar.selectbox("Choose A Voice", [ "aura-athena-en", "aura-asteria-en", "aura-stella-en","aura-luna-en","aura-orion-en","aura-perseus-en","aura-helios-en" ], index=0) #header for page st.header("Use Voice Assitant Aura") #LLM for transcribing the audio and giving a resonse(Speech to Text, and LLM) client = Groq( api_key=os.getenv("GROQ_API_key") ) #Package for Deepgram(Speech to Text Model) from deepgram import( DeepgramClient, SpeakOptions, ) #function for converting or transcribing audio to text def audio_to_text(client, audio_path): with open(audio_path,"rb") as audio_file: transcript = client.audio.transcriptions.create(model= "whisper-large-v3-Turbo",file=audio_file) print(transcript.text) prompt = transcript.text return prompt #fucntion that will generate a response based on the text def generate_response(input_text): if "voicebot" not in st.session_state: st.session_state["voicebot"] = [] st.session_state.voicebot.append( {"role": "user", "content": input_text} ) completion = client.chat.completions.create( model= "llama3-8b-8192", messages= st.session_state.voicebot, stream=True, temperature=0.7, max_tokens=300, stop=None, top_p=1 ) response = " " for chunk in completion: response += chunk.choices[0].delta.content or "" print(response) return response filename = "output.mp3" #function get called to use text to speech model def text2speech(text_input): try: SPEAK_OPTIONS = {"text": text_input} deepgram = DeepgramClient( api_key= os.getenv("DEEPGRAM_API_KEY")) options = SpeakOptions( #using session state so the user can change the voices model= st.session_state.voice , encoding="linear16", container="wav" ) response = deepgram.speak.rest.v("1").save(filename, SPEAK_OPTIONS, options) return response.content except Exception as e: print(f"Exception: {e}") #autoplay the audio file after the text to speech model has evaluated it def autoplay_audio(file_path: str): with open(file_path, "rb") as f: data = f.read() b64 = base64.b64encode(data).decode() md = f""" <audio controls autoplay="true"> <source src="data:audio/mp3;base64,{b64}" type="audio/mp3"> </audio> """ st.markdown( md, unsafe_allow_html=True, ) #load css file def load_css(file_path): with open(file_path) as f: st.html(f"<style>{f.read()}</style>") css_path = pathlib.Path("./assets/style.css") load_css(css_path) #voice assitant Aura with st.container(key="aura"): st.title("AURA") st.markdown("""<div class="spinner"> <div class="spinner1"></div> </div>""", unsafe_allow_html=True) voice = audio_recorder(text="", recording_color="#181a9e", neutral_color="#c2bfb8", icon_size="40px", key = "voiceai") #play voice when you hit the button if voice: voice_file= "tovoice.mp3" with open( voice_file, "wb") as f: f.write(voice) stt = audio_to_text(client, voice_file) response = generate_response(stt) file = text2speech(response) hide_audio = """ <style> audio { display : none !important; position: absolute !important;} </style> """ st.markdown(hide_audio, unsafe_allow_html=True) #audio played st.button("Stop response", key="stop", on_click=reset_chat, type="primary", help="stoping response clears history") st.audio("output.mp3", format="audio/mp3", autoplay=True) translation = audio_to_text(client, voice_file)
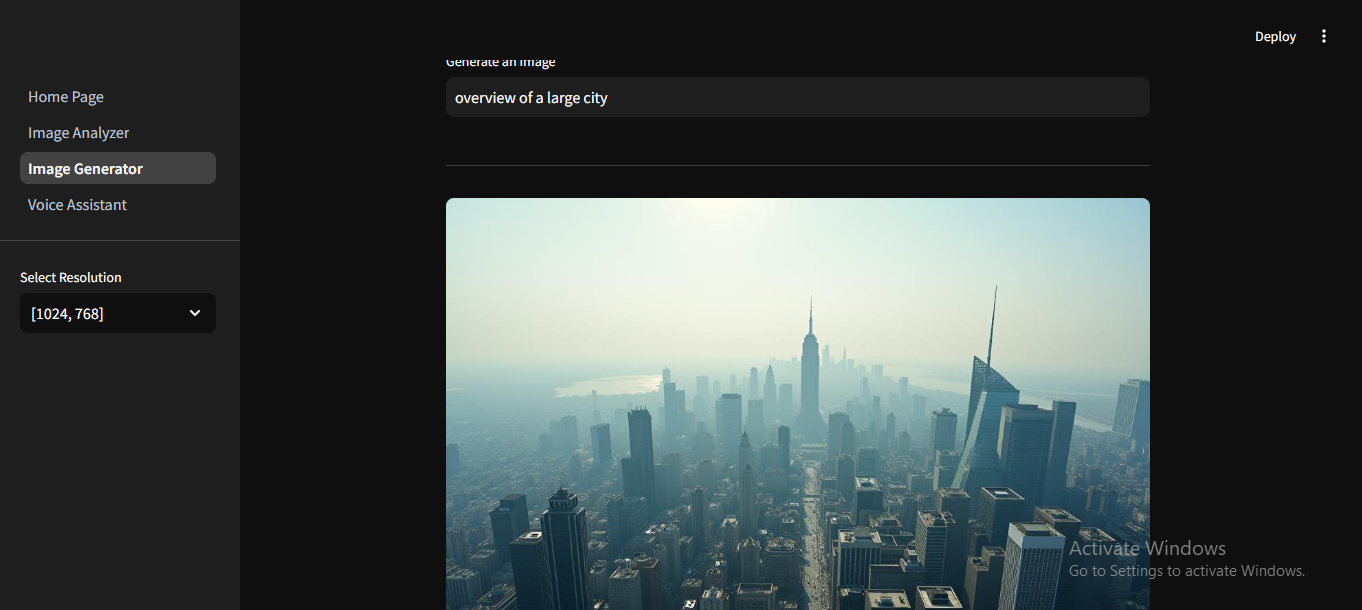
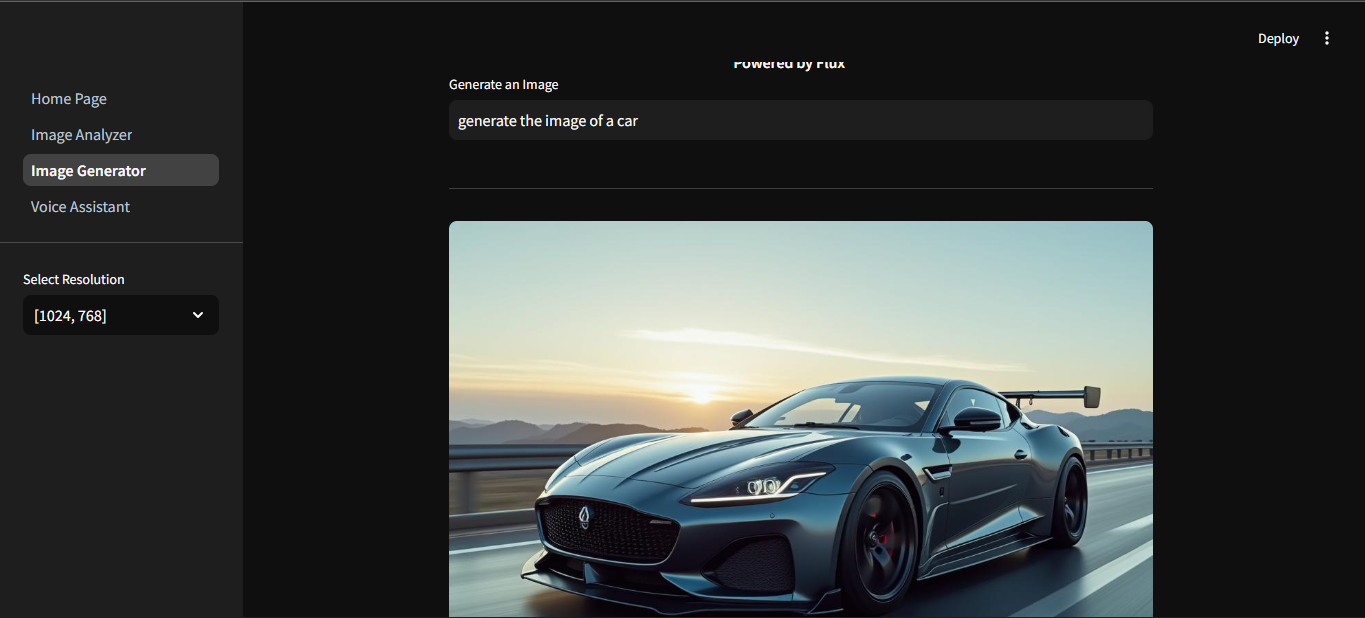
the system allows user to give a simple prompt to generate an image, and allows to pick the dimension and resolution of the output image
if "height" not in st.session_state: st.session_state["height"] = "" #store different height of an image in a session state st.session_state.height = st.sidebar.selectbox("Select Resolution", [ #all values must be a multiple of 16 [1024,768],[7680,4230],[3840,2160],[2560,1440], [1920,1080], [1280,720],[720,480],[640,360],[320,240] ], index=0) @st.cache_data def load_image(image_file): img = Image.open(image_file) return img #generate image after proving the prompt if prompt: with st.spinner("Generating image"): #Model parameters for generating images response = client.images.generate( prompt = prompt, model = "black-forest-labs/FLUX.1-dev", width=st.session_state.height[0], height=st.session_state.height[1], steps = 28, n=1, response_format ="b64_json" ) #converting the response to base64json image_data = response.data[0].b64_json #converting image json values to bytes that can be interepreted image_bytes = base64.b64decode(image_data) #make a directory called images in the environment os.makedirs("images", exist_ok=True) #index for all the files generated image_index =1 #set the path of each file to images folder image_path = os.path.join("images",f"generated_image {image_index}.png") while os.path.exists(image_path): image_index+=1 image_path = os.path.join("images",f"generated_image {image_index}.png") #open the file then with open(image_path, "wb") as image_file: image_file.write(image_bytes) #display the generated image st.image(image_path, caption="Generated Image")
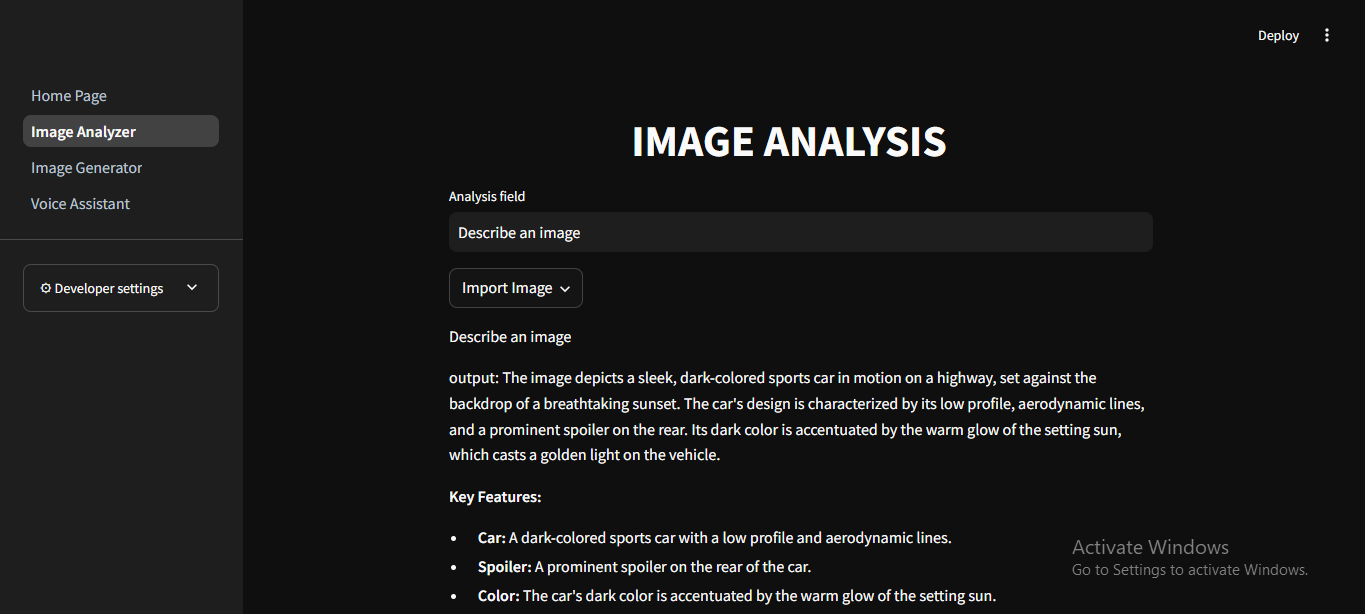
Analysis Model: The user can give a simple prompt, "whether it is to describe an image" or "solve this math question" the model will deliver an accurate response
prompt= st.text_input("Analysis field", value="Describe an image") with st.popover("Import Image"): uploaded_file = st.file_uploader("Upload an image", type=["png","jpg"]) def encode_image(image_path): with open(image_path, "rb") as image_file: return base64.b64encode(image_file.read()).decode('utf-8') def image_to_text(valuex,base64_image): prompt chat_completion = img_client.chat.completions.create( messages =[{ "role": "user", "content": [{"type":"text","text":valuex},{"type":"image_url", "image_url":{"url": f"data:image;base64,{base64_image}"}}] } ], model = "llama-3.2-11b-vision-preview", temperature=temp, max_tokens=max_tokens, stop=stop_seq, top_p=top_p ) print(chat_completion.choices[0].message.content) return chat_completion.choices[0].message.content if uploaded_file is not None and prompt: # Open the image image = Image.open(uploaded_file) # Define save directory save_folder = "uploads" os.makedirs(save_folder, exist_ok=True) # Ensure the folder exists # Save image with the original filename save_path = os.path.join(save_folder, uploaded_file.name) image.save(save_path) base64_image = encode_image(save_path) described_img = image_to_text(prompt,base64_image) st.write(f"output: {described_img}") elif uploaded_file is not None: st.write("Please Input a prompt, then press enter in the analysis field")
my method of review was a formative feedback with a small focus group
ASKBOT is an interactive multi-modal system that allows users to pick which method of interaction they would want to use, it is fast, delivers accurate response, delivers clear visuals to user and describes imagery with near perfect details.