This project aims to develop a real-time sign language detection model leveraging Mediapipe for hand landmark detection, OpenCV for image processing, and gTTS for converting recognized text into speech. The model enables real-time communication between sign language users and others by recognizing gestures and generating corresponding spoken text.
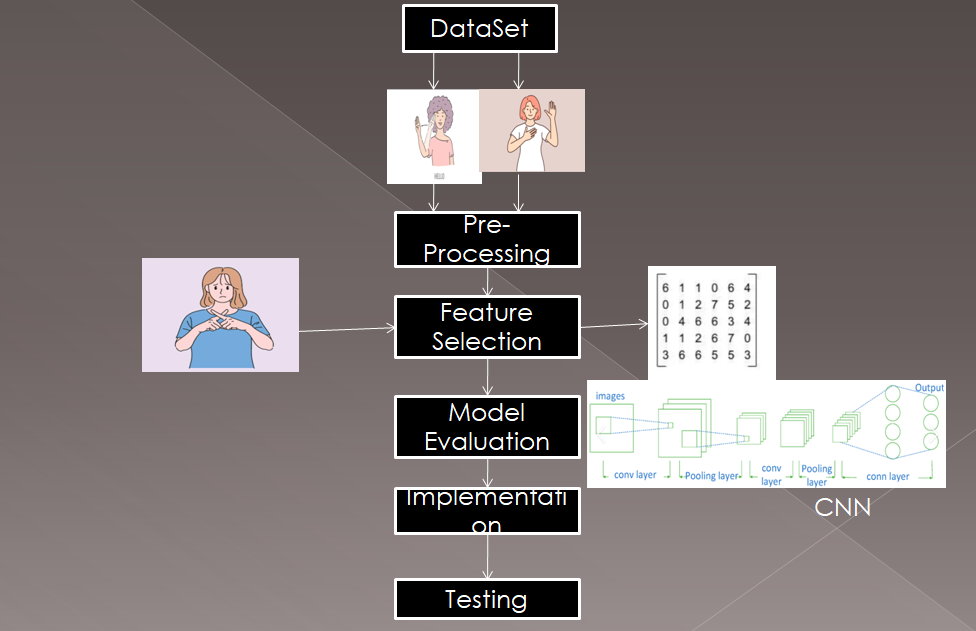
The dataset consists of images of hand gestures corresponding to sign language labels. Using OpenCV, images are captured from a webcam and organized into folders for training purposes.
# Create folders and capture images for label in labels: label_path = os.path.join(IMAGES_PATH, label) os.makedirs(label_path, exist_ok=True) cap = cv2.VideoCapture(0) print('Collecting images for {}'.format(label)) time.sleep(5) for imgnum in range(number_img): ret, frame = cap.read() imagename = os.path.join(label_path, '{}.jpg'.format(str(uuid.uuid1()))) cv2.imwrite(imagename, frame) cv2.imshow('frame', frame) time.sleep(2) if cv2.waitKey(1) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows() print('Image collection completed!')
Mediapipe is used to extract hand landmarks, which are preprocessed and normalized to prepare the data for the CNN model.
# import numpy as np import mediapipe as mp # Function to preprocess Mediapipe landmarks def preprocess_landmarks(landmarks): landmarks = np.array([[lm.x, lm.y, lm.z] for lm in landmarks]).flatten() landmarks = (landmarks - np.mean(landmarks)) / np.std(landmarks) # Normalize return landmarks[:63].reshape(1, -1) # Reshape for CNN input
The CNN model is designed to classify the preprocessed landmarks into one of the nine labels.
# from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, LeakyReLU, BatchNormalization, Dropout # Define the CNN model model = Sequential() model.add(Dense(256, input_shape=(63,))) model.add(LeakyReLU(alpha=0.1)) model.add(BatchNormalization()) model.add(Dropout(0.5)) model.add(Dense(128)) model.add(LeakyReLU(alpha=0.1)) model.add(BatchNormalization()) model.add(Dropout(0.5)) model.add(Dense(64)) model.add(LeakyReLU(alpha=0.1)) model.add(BatchNormalization()) model.add(Dropout(0.5)) model.add(Dense(9, activation='softmax')) # Compile the model model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Real-time detection is performed using Mediapipe for hand tracking, and the landmarks are processed and passed through the trained CNN model for prediction.
# cap = cv2.VideoCapture(0) mp_hands = mp.solutions.hands hands = mp_hands.Hands() while cap.isOpened(): ret, frame = cap.read() image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) results = hands.process(image) if results.multi_hand_landmarks: for hand_landmarks in results.multi_hand_landmarks: landmarks = preprocess_landmarks(hand_landmarks.landmark) prediction = model.predict(landmarks) label = labels[np.argmax(prediction)] # Display the prediction on the video feed cv2.putText(frame, label, (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2, cv2.LINE_AA) cv2.imshow('Real-Time Detection', frame) if cv2.waitKey(10) & 0xFF == ord('q'): break cap.release() cv2.destroyAllWindows()
The detected gesture is converted into text and then into speech using the gTTS library.
# from gtts import gTTS import os # Function to convert text to speech def text_to_speech(text): tts = gTTS(text, lang='en') tts.save('output.mp3') os.system('start output.mp3')
This project showcases a complete pipeline for real-time sign language detection, from dataset generation to gesture classification and text-to-speech conversion. The integration of Mediapipe, OpenCV, and gTTS makes it an accessible and efficient tool for breaking communication barriers between sign language users and others.
[https://github.com/Ankitach780/American-Sign-Language-Detection]