Building an AI Image Captioner
Table of Contents
Introduction
This project explores the fascinating intersection of computer vision and natural language processing by building an AI that generates captions for images. Leveraging a combination of convolutional neural networks (CNNs) for image encoding and recurrent neural networks (RNNs) for decoding captions, the goal is to create a system capable of producing human-like descriptions of images. This guide will take you step-by-step through creating the model and the rationale behind each decision. It will then go into training and testing the model. By the end, you should feel confident in creating a personalized neural network and training it.
Why Caption Images?
Image captioning has applications in accessibility (e.g., assisting visually impaired individuals), search engines, and multimedia content generation. The project aims to demonstrate how models can bridge the gap between visual data and text. Image captioning is a pretty straightforward task, and is one that is easy to measure the relative success of after training, which is why I used it for this guide.
Prerequisites
Before getting started, ensure you have the following:
- Python 3.8+
- Libraries: PyTorch, NumPy, Matplotlib, Pillow (you will pip install these later, so don't worry about it)
- Google Colab for GPU-based training (optional but recommended)
- Basic understanding of neural networks, especially CNNs and RNNs (not necessary but will make it easier to follow)
Messing Around with the Model
Before getting into the tutorial, feel free to mess around with the code I have created for this. It contains a bunch of python scripts, a README file to explain the project (similar to this), and a requirements.txt file that contains every library you need to run this code. Look at the project structure below:
project-root
├── src
│ ├── main.py # Main driver script
│ ├── dataset.py # Data loading and preprocessing
│ ├── utils.py # Helper functions (e.g., tokenization, vocabulary)
│ ├── model.py # Encoder-Decoder model definitions
│ ├── train.py # Training loop
│ ├── inference.py # Testing script
├── requirements.txt # Python dependencies
└── README.md # Project documentation
Now to actually run the code, follow these steps:
- Clone the repository:
git clone https://github.com/wkraz/ai-image-captioning.git cd ai-image-captioning - Set up a virtual environment and install dependencies:
python3 -m venv .venv source .venv/bin/activate # For Linux/Mac .venv\Scripts\activate # For Windows pip install -r requirements.txt - Now, just run the testing script (it uses an image I uploaded, but you can change it):
python src/inference.py
Creating the Model
Creating an environment
Before we write any code, first we need to set up an environment (and optionally connect to GitHub). First, create a directory in your terminal:
mkdir ai-image-captioning # feel free to pick any name cd ai-image-captioning
Next, create the necessary files
mkdir src touch src/main.py touch src/dataset.py touch src/utils.py touch src/model.py touch src/train.py touch src/inference.py touch README.md touch requirements.txt
Now, that we've created the necessary files, open up your favorite IDE (I recommend VS Code) so we can actually edit the files. Once you do so, copy the following into your requirements.txt file (these are the libraries we'll need):
torch torchvision nltk pandas python-dotenv pillow
Once you've done that, create a virtual environment so we can download the requirements locally:
python3 -m venv .venv source .venv/bin/activate # For Linux/Mac .venv\Scripts\activate # For Windows pip install -r requirements.txt
Now we're ready to actually code!
Creating the initial model
Step 1: Vocabulary and Caption Processing
The first step to creating this model is building a vocabulary for this model and can make sense of captions. Computers don't understand words, so saying "the dog in the park" means absolutely nothing to them. We are creating a neural network, and neural networks work with integer arrays.
Don't worry about the actual network, just look at the type of inputs/outputs. The inputs are just integers, and there are n integers being passed to the input, meaning we must pass an integer array to the neural network. The neural network that we're going to create will take images as inputs and output captions. So, we need to find a way to turn images into integers and integers into captions. The way we're going to do this is by creating a vocabulary that creates consistency between words using special tokens like <bos> (beginning of sentence) and <eos> (end of sentence). Here is a code chunk (we're working in src/utils.py:
from nltk.tokenize import TreebankWordTokenizer from collections import Counter # Builds a vocabulary from all the tokenized captions in the dataset # Captions are stored in a dictionary where keys are image IDs and values are lists of captions # Example captions_dict: {'image1.jpg': ['A man riding a horse', 'A person on a horse']} def build_vocab(captions_dict, min_freq=1): counter = Counter() for captions in captions_dict.values(): for caption in captions: tokens = tokenize_caption(caption) counter.update(tokens) # Start building the vocabulary dictionary with special tokens vocab = {"<pad>": 0, "<unk>": 1, "<bos>": 2, "<eos>": 3} # Padding, unknown, start, end tokens # Add tokens that appear more than or equal to `min_freq` times for word, count in counter.items(): if count >= min_freq: vocab[word] = len(vocab) return vocab # completed vocabulary dictionary
- Input: A dictionary of image IDs and their associated captions.
- Process:
- Each caption is tokenized into individual words (lowercased for consistency).
- Word frequencies are calculated using
Counter. - Words that meet the minimum frequency threshold (
min_freq) are added to the vocabulary. - Special tokens like
<pad>and<bos>are reserved for functionality (e.g., padding sequences or indicating sentence start).
- Output: A dictionary where each word is mapped to a unique integer index.
Step 2: Data Loading
Now, we will implement the dataset loader in src/dataset.py to handle image-caption pairs. We are doing this so we can look at images (like the ones in the Flickr8kdataset), and turn them into a more useable format. More explicitly, we will input the path to an image, and its corresponding caption (which is stored in captions_dict), and we will output a tuple (just a way to store 2 different things in a single variable) that contains the image in a preprocessed tensor form (we'll explain this in a bit) and a caption string. Here is some code (in src/dataset.py):
from torch.utils.data import Dataset from PIL import Image # Dataset class to handle the Flickr8k dataset # This is Object Orienting Programming, don't worry if you've never seen this before class Flickr8kDataset(Dataset): def __init__(self, images_path, captions_dict, transform=None): self.images_path = images_path # Directory containing images self.captions_dict = captions_dict # Dictionary of image captions self.image_ids = list(captions_dict.keys()) # List of all image IDs self.transform = transform # Transformation pipeline for preprocessing images def __len__(self): return len(self.image_ids) # Total number of images in the dataset def __getitem__(self, idx): image_id = self.image_ids[idx] # Get the image ID at the given index image_path = os.path.join(self.images_path, image_id) # Construct the full image path # Open and preprocess the image image = Image.open(image_path).convert('RGB') # Convert to RGB if self.transform: image = self.transform(image) # Apply transformations caption = self.captions_dict[image_id][0] # Use the first caption associated with the image return image, caption # Return the preprocessed image and its caption
Here is a bit of an explanation on what's happening:
- Input: Paths to images and their corresponding captions (stored in
captions_dict). - Process:
- The
__getitem__method retrieves an image and its first associated caption based on an index. - Images are opened, converted to RGB format, and preprocessed (e.g., resized, normalized).
- The
- Output: A tuple containing a preprocessed image tensor and a caption string.
Again, don't worry too much about the object-oriented syntax. Just focus on the high level details, which are that this code gives us a nice way to look at images in the Flickr8kdataset (applicable to any other dataset too) and pass them to our neural network in a more convenient way.
Step 3: The Encoder Model
Time to actually build the neural network we've been talking about so much! We'll separate the neural network into 2 parts. The first part we'll build is the Encoder, which will be responsible for looking at images and extracting key things from the images that help the network identify it (in an image of a dog in a park, it would extract features like leaves, grass, fur, paws, etc and the network will piece that all together to determine it's a dog in a park). The other feature we'll build is the Decoder, which will look at all the knowledge the model has gained of the image and turn it into a caption that describes it. To build our encoder, we will use a pre-trained model called ResNet contained in PyTorch. ResNet is very good at image detection, so it's perfect for what we need. Here is a chunk of code in src/model.py that will create our Encoder model:
import torchvision.models as models # Encoder model based on ResNet-50 class Encoder(nn.Module): def __init__(self, encoded_image_size=14, embed_size=256): super(Encoder, self).__init__() resnet = models.resnet50(pretrained=True) # Load a pre-trained ResNet-50 model # Remove the last fully connected layer of ResNet self.encoder = nn.Sequential(*list(resnet.children())[:-2]) # Adaptive pooling to standardize feature map size self.pool = nn.AdaptiveAvgPool2d((encoded_image_size, encoded_image_size)) # Fully connected layer to map features to the embedding size self.fc = nn.Linear(401408, embed_size) # Adjust based on ResNet output size def forward(self, images): features = self.encoder(images) # Pass the images through ResNet features = self.pool(features) # Apply adaptive pooling features = features.view(features.size(0), -1) # Flatten the features features = self.fc(features) # Map to embedding size return features
Explanation:
- Input: A batch of images.
- Process:
- Images are passed through a ResNet-50 CNN to extract feature maps.
- Feature maps are pooled to a fixed size.
- A fully connected layer reduces the feature dimensions to a fixed embedding size.
- Output: A feature vector representing each image.
Again, don't worry about a lot of the syntax, focus more on the logic behind it. We are inputting a bunch of images, and using a pre-trained model to look at these images and extract important features from them. These features are then turned into a vector of integers which we'll pass to the decoder, who will use this vector to create relevant captions.
Step 4: The Decoder Model
Now, we'll finish src/model.py and create the Decoder class. As described above, the decoder will take an input vector and output a caption that is hopefully accurate. Instead of using a ResNet model, we're going to use a LSTM model, since we're not looking at images anymore and the LSTM model fits what we need a bit better. A lot of the logic is the same as above, so let's just dive into the code
import torch.nn as nn # Decoder model based on LSTM class Decoder(nn.Module): def __init__(self, vocab_size, embed_size, hidden_size, num_layers=1): super(Decoder, self).__init__() self.embed = nn.Embedding(vocab_size, embed_size) # Embedding layer to convert words to dense vectors self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True) # LSTM for sequence modeling self.linear = nn.Linear(hidden_size, vocab_size) # Fully connected layer to predict vocabulary scores def forward(self, features, captions): # Expand image features to match the sequence format features = features.unsqueeze(1) # (batch_size, 1, embed_size) # Embed the captions embeddings = self.embed(captions) # (batch_size, seq_length, embed_size) # Concatenate the features and embedded captions inputs = torch.cat((features, embeddings), dim=1) # (batch_size, seq_length+1, embed_size) # Pass the concatenated inputs through the LSTM outputs, _ = self.lstm(inputs) # (batch_size, seq_length+1, hidden_size) # Map the LSTM outputs to the vocabulary size outputs = self.linear(outputs) # (batch_size, seq_length+1, vocab_size) return outputs
- Input: Encoded image features and tokenized captions.
- Process:
- Convert captions to dense word embeddings using the embedding layer.
- Concatenate the image features with the embedded captions.
- Pass the combined inputs through the LSTM to model sequential dependencies.
- Use a fully connected layer to predict the next word at each time step.
- Output: A sequence of word probabilities for the vocabulary.
As described, our decoder will look at a vector of image features and combine them using its understanding of the relationship between features and words, and generate a "sequence of word probabilities". This sequence is essentially an array of numbers between 0-1 that describe how confident the model is that each word is in the image, where a 0 is no confidence and a 1 is complete confidence. Here is an example of a similar style of decoder:
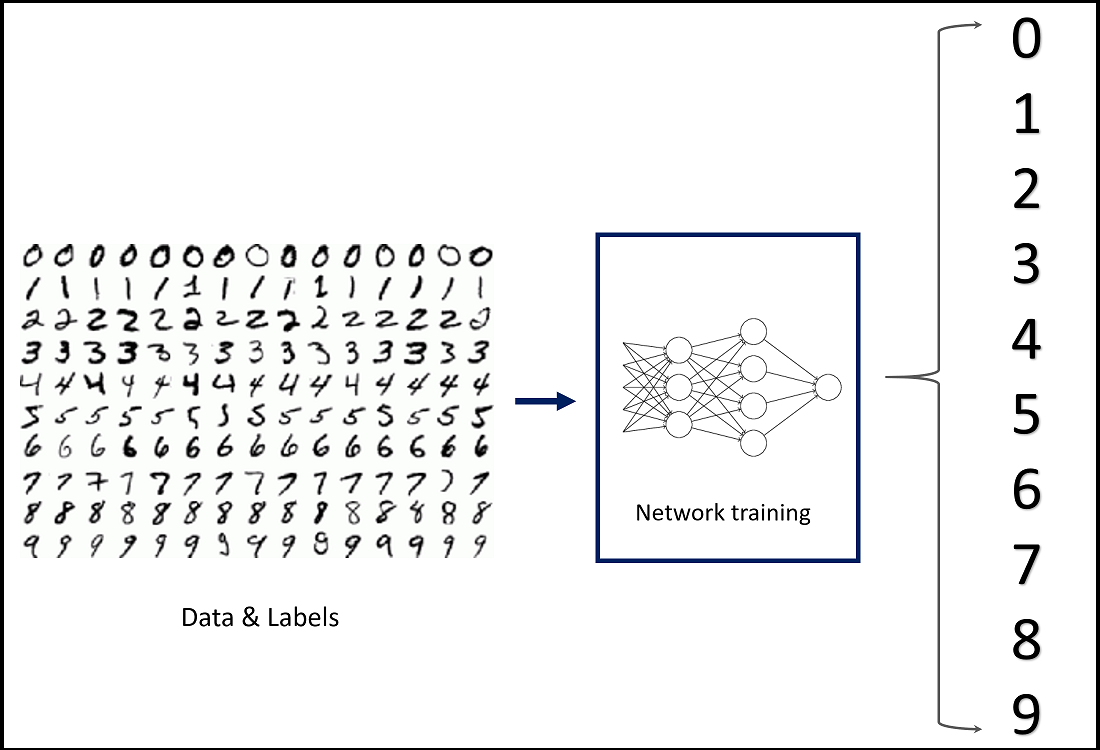
This is maybe the most famous neural network example ever, and for good reason. A handwritten number is input, the network does a bunch of calculations to figure out which number it most likely is, and a neuron for each number from 0 to 9 is lit up with a value from 0 to 1 that represents how confident the model is that it is the number. Our decoder is doing the same thing, but with every word in its vocabulary (it is capped to mostly simple words or else this would be impossible). We can then use this confidence array to figure out what it's most likely that the network identified in the image, and create a relevant caption that matches the style of the captions the model has seen before.
Step 5: Create a Driver
Now, we've got all the logic we need, so we can tie it all together in src/main.py. Main.py will load the dataset, initialize the models, and start the training process. Because of how large our dataset is (literally 8,000 images with each having 5+ captions), we will use a GPU which speeds up computations a ton. We will use Google Colab, because it's the easiest to get set up with. Colab uses NVIDIA CUDA GPUs, so we just need to add a couple lines of code to account for that and then we'll be good. Here is the driver code:
import torch from dataset import get_dataloader from model import Encoder, Decoder from train import train_model from utils import build_vocab, load_captions def main(): # Set device to CUDA if available print("Starting main function") device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"Using device: {device}") # Load captions and vocabulary print("Loading captions and vocabulary...") captions_dict = load_captions() # Load the captions dataset vocab = build_vocab(captions_dict) # Build the vocabulary from captions print("Captions and vocabulary loaded") # Create dataloader print("Creating dataloader...") dataloader = get_dataloader(captions_dict) # Initialize the DataLoader print("Dataloader loaded") # Model parameters embed_size = 256 hidden_size = 512 vocab_size = len(vocab) # Vocabulary size determines the output dimension of the decoder # Initialize encoder and decoder on the specified device print("Initializing encoder and decoder...") encoder = Encoder(embed_size=embed_size).to(device) # Initialize encoder decoder = Decoder(vocab_size, embed_size, hidden_size).to(device) # Initialize decoder print("Encoder and decoder initialized") # Train the model print("Training model...") train_model(encoder, decoder, dataloader, vocab, device=device) # Start the training process print("Model trained.") if __name__ == "__main__": main()
- Device Setup: The program checks for CUDA availability and sets the device accordingly.
- Load Captions and Vocabulary: Captions are loaded, tokenized, and used to build a vocabulary.
- Initialize Dataloader: A PyTorch DataLoader is created to manage batches of image-caption pairs during training.
- Initialize Models: The Encoder and Decoder models are instantiated and moved to the appropriate device.
- Train the Model: The
train_modelfunction is called to train the encoder-decoder pipeline.
The driver script just ties together everything we did and incorporates GPU training to make our lives easier. It loads the data we need,
initializes all the models, and starts the training loop, acting as the entry point to our program: in Colab all you need to do is run python src/main.py
Step 6: Training the Model
Now, we'll implement the training loop that we call in main.py. What happens in the training is we will split the images into epochs (just batches that get looked at together). We'll look at each image in the epoch, and we'll create a caption that we think matches it. We'll then compare our caption to the actual caption, and quantify how far off it is through a "loss function", which will return a number from 0-100 that says how bad our guess was, basically. Our goal is to minimize this. It will then do this for each image in the epoch, and once it reaches the end it will aggregate the average loss for an image in that epoch. It will then take note of the weights that contributed to the loss the most, and it will adjust them. It will then apply these new weights to the next epoch, and the average loss SHOULD decrease. A sign of a good neural network is one where the loss decreases each epoch, for this reason. In training the model, I started at an average loss around 4.4 on epoch 1/5, and ended with an average loss of 2.4204 on epoch 5/5. To actually get these weights, we store them in variables: encoder_final.pth and decoder_final.pth, and then upload them into the testing script. Here is the code for the training loop in colab:
import torch.optim as optim from torch.nn.utils.rnn import pad_sequence # Convert a caption to a tensor using the vocabulary # Example: "a dog runs" -> [2, 10, 20, 15, 3] (where 2 = <bos>, 3 = <eos>) def caption_to_tensor(caption, vocab): tokens = ["<bos>"] + tokenize_caption(caption) + ["<eos>"] # Add <bos> and <eos> return torch.tensor([vocab.get(token, vocab["<unk>"]) for token in tokens], dtype=torch.long) # Main training loop def train_model(encoder, decoder, dataloader, vocab, device, num_epochs=5, learning_rate=1e-3): criterion = nn.CrossEntropyLoss(ignore_index=vocab["<pad>"]).to(device) # Loss function ignoring padding optimizer = optim.Adam(list(encoder.parameters()) + list(decoder.parameters()), lr=learning_rate) # Adam optimizer for epoch in range(num_epochs): total_loss = 0 for images, captions_batch in dataloader: images = images.to(device) # Convert captions to tensors and pad them caption_tensors = [caption_to_tensor(caption, vocab).to(device) for caption in captions_batch] captions = pad_sequence(caption_tensors, batch_first=True, padding_value=vocab["<pad>"]) inputs = captions[:, :-1] # Exclude the last token for inputs targets = captions[:, 1:] # Shift targets by one token # Forward pass features = encoder(images) outputs = decoder(features, inputs) # Compute loss loss = criterion(outputs.reshape(-1, len(vocab)), targets.reshape(-1)) # Backpropagation and optimization optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss / len(dataloader):.4f}")
- Input: Preprocessed image-caption pairs, encoder and decoder models, vocabulary, and training parameters (e.g., learning rate, number of epochs).
- Process:
- Pass each image in the batch through the encoder to extract feature vectors.
- Tokenize the captions and convert them into tensors using the vocabulary.
- Use the decoder to predict a sequence of words based on the image features and previous word predictions.
- Compare the predicted sequence to the ground truth caption using a loss function (CrossEntropyLoss).
- Backpropagate the loss to adjust model weights and improve future predictions.
- Repeat for all batches in the epoch and calculate the average loss.
- Iterate through multiple epochs, applying updated weights to minimize the loss.
- Output: Trained encoder and decoder models, with weights saved as
encoder_final.pthanddecoder_final.pth.
The training loop optimizes the model to minimize the average loss across epochs, enabling it to generate captions that closely align with the dataset's ground truth descriptions.
Step 7: Testing the Model
Now that we've got a trained model, let's write a script to actually test it and see what we've built. If we don't like it, we can train it on more data, or completely start over and tweak the neural network structure. We will write src/inference.py to look at unseen images and generate a caption. Here's the code:
import torch from torchvision import transforms from PIL import Image from model import Encoder, Decoder from utils import load_captions, build_vocab # Function to generate a caption using greedy decoding def generate_caption(encoder, decoder, image, vocab, max_length=20, device="cpu"): inv_vocab = {v: k for k, v in vocab.items()} # Reverse vocabulary to map indices back to words image = transform(image).unsqueeze(0).to(device) # Preprocess the image and add batch dimension features = encoder(image) # Extract image features inputs = torch.tensor([vocab["<bos>"]], dtype=torch.long).unsqueeze(0).to(device) # Start token caption = [] for _ in range(max_length): outputs = decoder(features, inputs) # Predict the next word _, predicted = outputs[:, -1, :].max(dim=1) # Get the word with the highest probability word_idx = predicted.item() if word_idx == vocab["<eos>"]: # Stop if the end-of-sentence token is generated break caption.append(inv_vocab.get(word_idx, "<unk>")) inputs = torch.cat([inputs, predicted.unsqueeze(0)], dim=1) # Add predicted word to inputs return ' '.join(caption) # Return the generated caption as a string # Test the model on a new image def main(): image_path = "../path/to/test/image.jpg" # Replace with the path to your test image image = Image.open(image_path).convert("RGB") # Transform for preprocessing the image transform = transforms.Compose([ transforms.Resize((299, 299)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) print("Loading model and vocabulary...") captions_dict = load_captions() # Load captions to build vocab vocab = build_vocab(captions_dict) encoder = Encoder(embed_size=256).to(device) decoder = Decoder(len(vocab), embed_size=256, hidden_size=512).to(device) encoder.load_state_dict(torch.load("encoder_final.pth", map_location=device)) decoder.load_state_dict(torch.load("decoder_final.pth", map_location=device)) encoder.eval() decoder.eval() print("Generating caption...") caption = generate_caption(encoder, decoder, image, vocab, device=device) print("Generated Caption:", caption) if __name__ == "__main__": main()
- Input: A preprocessed image and trained encoder-decoder models.
- Process:
- Preprocess the image by resizing, normalizing, and converting it to a tensor.
- Pass the image through the encoder to extract a vector of features that represent its visual content.
- Begin generating a caption by initializing with the
<bos>token. - Use the decoder to predict the next word in the caption by processing the image features and previously predicted words.
- Stop generation when the
<eos>token is produced or the maximum length is reached.
- Output: A sequence of words forming a human-readable caption describing the input image.
As described, the inference process uses the trained encoder-decoder pipeline to analyze the image and generate a natural language description. The decoder predicts one word at a time, producing a "sequence of word probabilities" for the vocabulary. Each word probability reflects how confident the model is about its inclusion in the caption. It then synthesizes all of these and turns it into a sequence of words that makes the most sense to a human.
Conclusion
This project has demonstrated how to bridge the gap between visual data and natural language by building an AI image captioning system from scratch. Through each step—vocabulary building, data loading, creating and training the encoder-decoder model, and finally testing—we explored the complexities of designing and training a neural network capable of generating human-like captions for images.
By using a combination of a pre-trained ResNet encoder and an LSTM-based decoder, we were able to harness the power of deep learning to extract meaningful visual features and translate them into coherent captions. Training the model on the Flickr8k dataset allowed us to test its ability to generalize and generate accurate descriptions for unseen images.
One of the highlights of this project was seeing the model in action during testing, where it analyzed new images and produced captions based on its training. While there is always room for improvement in fine-tuning the model or increasing dataset size, the results illustrate the potential of combining computer vision and natural language processing.
This project is just the beginning. The skills and knowledge gained here—working with neural networks, handling datasets, and implementing complex models—can be extended to solve more advanced problems in AI, such as video captioning, question answering from images, or even real-time accessibility tools for visually impaired users.
If you’ve followed along, I hope this tutorial has given you a solid foundation in building an AI model and the confidence to experiment with and improve upon this work. Feel free to share your thoughts, ask questions, or showcase your own projects inspired by this guide. The possibilities with AI are endless—this is just the start!