![]()
AI Assistant VUI
An experimental voice user interface (VUI) to interact with an AI assistant.
It is as a client CLI that connects to an OpenAI API-compatible server (that is served locally by LocalAI).
To answer a user request it can decide to use tools in form of running configurable, dockerized functions.
For voice activity detection (VAD) silero-vad is built into the client.
For chat completion, speech-to-text (STT) and text-to-speech (TTS) capabilities the client leverages the API server.
In order to detect whether the AI assistant is addressed, a wake word can be configured.
Though, wake word support is implemented by matching the STT (whisper) output string against the wake word, requiring all voice communication to be STT processed, at least for now.
Motivation
One day I was in the kitchen cooking when my Mopidy-based streamer started playing a song that I didn't like.
I wanted to skip the song or at least turn the volume down but, since I had dirty fingers, I couldn't simply use my phone or computer mouse, unless I'd clean them.
Having a freely configurable VUI would be a great addition to a graphical user interface (GUI) in such a situation and for IoT devices in general since the user wouldn't have to touch a screen or mouse to skip the song.
Similarly, such a VUI backed by a Large Language Model (LLM) could allow disabled and old people to use computers (more intuitively).
Potentially there are also other use-cases such as a personal advisor or a translator (also see Babelfish) for everyone.
While there are already commercial, cloud-based products such as Amazon Alexa available that address some of these problems to some degree, they are not as capable and flexible as the latest LLMs, not freely configurable, not open source but they come with a vendor lock-in, require an internet connection, listen to everything that anyone around them says and send it to 3rd party servers, impacting their users' privacy negatively.
Given the latest advancements of AI technology, I was curious whether a VUI could already be implemented based on open source software without those limitations, preferably in Go, and started researching.
Features/requirements
- A voice-controlled AI assistant that can interact with the real world using preconfigured tools: e.g. can decide to run a docker container to change the music volume.
- Low latency/near-realtime response to support a fluent, natural conversation.
- Verbally interruptable system in order to appear responsive and not waste the user's time by talking about irrelevant information. When interrupted, the assistant stops talking after it finished the current sentence and for consistency only what it really said ends up within the message history.
- Configurable wake word support to prevent the AI from responding to every voice communication (e.g. between humans) which is annoying otherwise. Any sentence the user says that does not contain the wake word is ignored by the AI.
- Save energy/API calls and avoid hallucination of the STT system by STT-processing only audio signals that contain voice activity (VAD).
Related work
- Historically dialog systems such as CMU Sphinx exist since a while already. However, these were quite unflexible since they required the user to say specific preconfigured phrases in order to trigger a response and they weren't as good at recognizing those as modern LLM-based solutions which are also more flexible since they do not require every possible dialog to be preconfigured.
- Commercial cloud/SaaS-based, closed-source voice-controlled assistants such as Amazon's Alexa, Google's Assistant, Apple's Siri. However, these products require an internet connection and send the recorded audio data to 3rd party servers, negatively impacting their users' privacy.
- OpenAI's whisper is the state-of-the-art speech recognition (STT) model and SaaS API.
- Commercial AI SaaS products such as OpenAI's ChatGPT started to support voice interaction recently.
- faster-whisper: An open source reimplementation of OpenAI's whisper that is even faster than the original.
- Silero VAD: An open source Voice Activity Detection (VAD) model, allowing to detect voice activity within an audio signal. This is useful to reduce hallucination of the STT/whisper model and also to reduce the computational load and therefore energy consumption since not every audio signal needs to be STT-processed.
- LocalAIVoiceChat: A Python-based conversational AI to talk to but without the ability to let the AI call user-defined functions.
- go-whisper-cpp-server-example: An STT-based translator written in Go.
- ollama: An open source LLM engine that implements an OpenAI-compatible chat completion API that can be run locally.
- LocalAI: An open source, OpenAI-compatible LLM API server that integrates ollama and faster-whisper along with other open source AI projects to support chat completion, STT and TTS locally. Therefore LocalAI is very well suited as the server of the AI Assistant VUI.
System requirements
- Processor: Intel Core i3/AMD Ryzen 3 or better.
- RAM: 4GB minimum, 8GB recommended.
- Graphics card with 8GB RAM (AMD or Nvidia).
- Storage: 1GB free space.
- Audio: Working microphone and speakers/headphones.
- Operating system: Linux (tested on an Ubuntu 24.04 host), adaptable for MacOS and Windows.
Build
Clone the repo:
git clone https://github.com/mgoltzsche/ai-assistant-vui.git cd ai-assistant-vui
To build the Linux container image, run the following command within the project's root directory (requires Docker to be installed):
make
Run
- Start the LocalAI API server (LLM server) by running the following within the project's root directory:
make run-localai
-
Browse the LocalAI web GUI at http://127.0.0.1
/browse/ and search and install the models you want to use. When using the default AI Assistant VUI configuration, you need to installwhisper-1(STT),localai-functioncall-qwen2.5-7b-v0.5(chat) andvoice-en-us-amy-low(TTS). -
Run the VUI (within another terminal):
make run-vui INPUT_DEVICE="KLIM Talk" OUTPUT_DEVICE="ALC1220 Analog"
You will likely have to replace the values of INPUT_DEVICE and OUTPUT_DEVICE with the names or IDs of your audio devices (available devices are listed in the log).
You may not be able to use an audio device when another program (e.g. your browser) is already using it.
In that case, please close other programs, wait a few seconds and then re-run the VUI.
You need to mention the configured wake word (defaults to "Computer") with each request to the AI assistant.
For instance you can ask "Computer, what's the capital of Germany?"
Implementation details
The application is written in Go, leveraging its static typing and concurrency features.
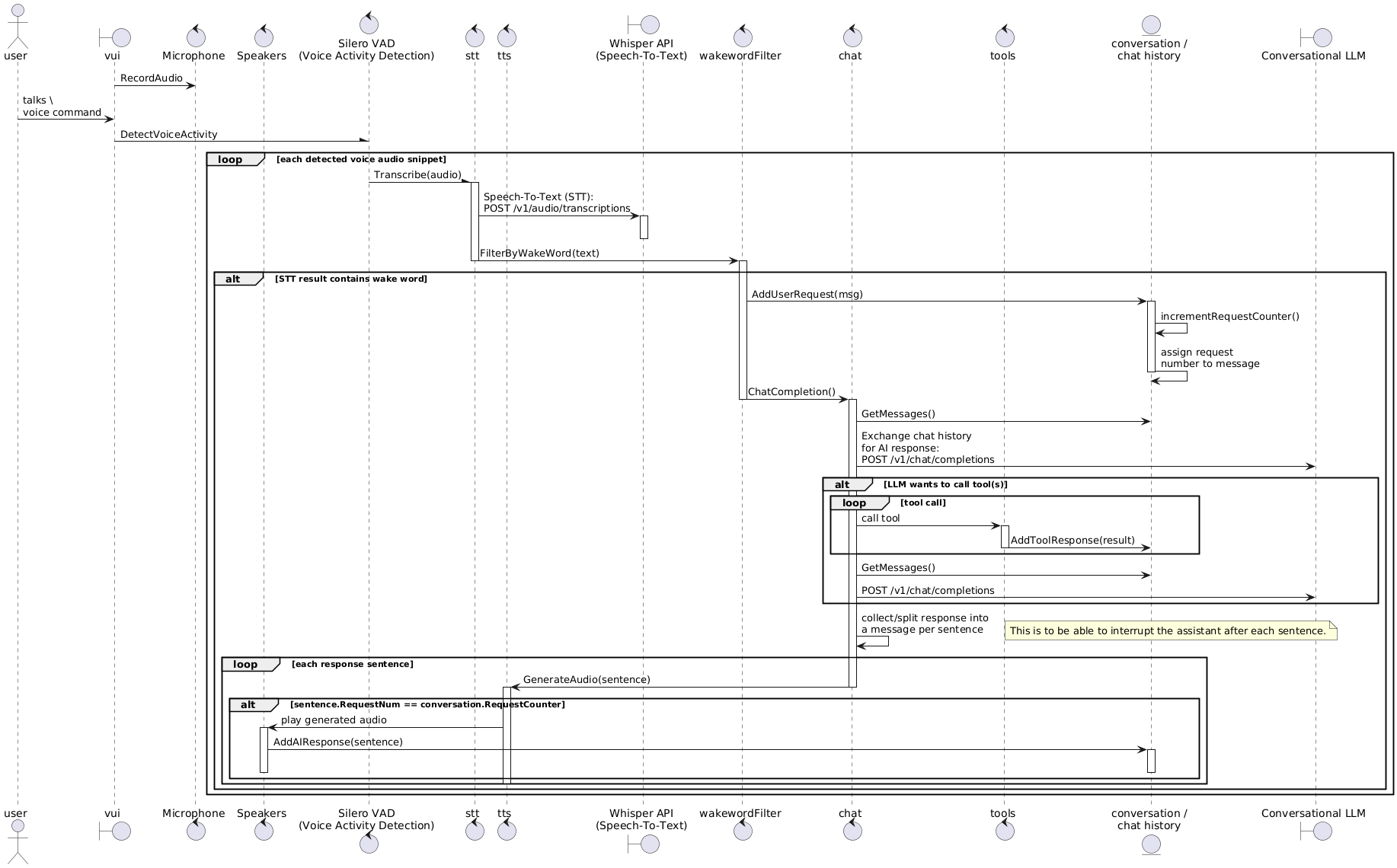
Schematic sequence diagram:
Limitations
- The wake word must be recognized by the whisper model - this could be improved potentially using a specialized wake word model.
- Context size and storage:
- To keep the context size minimal and speed up inference, tool results of the previous user request are deleted from the chat history with every new user request.
- The chat history is currently stored in-memory only and is therefore lost when restarting the application.
- The chat history is infinite / not truncated which therefore exceeds the LLM's context size at some point and then requires an application restart.
- Due to a LocalAI LLM bug function calls are often repeated infinitely - this is detected and prevented after the 2nd call.
- Audio device usage: The container does not work with pulseaudio but ALSA and therefore requires no other application to use the same audio devices it uses.
- Other people can also give the AI commands (e.g. somebody on the street shouting through the window) - voice recognition could protect against that.
Roadmap
- Context size and storage:
- Chat history retention: Detect when the maximum context size would be exceeded and delete old messages in that case, starting with the first user request and assistant response.
- To support multiple rooms and a client for each as well as remote access, the context/conversation history could be stored on a (local) server.
- Add Retrieval-Augmented Generation (RAG) support to kind of support an infinite context size: write conversations (and other personal information) into a vector database, query it for every user request to find related information and add it to the message history before sending it to the chat completion endpoint.
- Prevent function call repetition.
- Add a wake word engine in order to save energy/STT API requests.
- To improve compatibility, it would be good to make the container connect to pulseaudio.
- Authentication via voice recognition to make the assistant aware of who is talking and to protect against other people commanding the assistant.
Credits
When I searched the web for an existing implementation of such an application or similar to start with, I found the STT translator go-whisper-cpp-server-example from where I copied and adjusted a couple of code snippets.